
在 NLTK 中使用 Stanford NLP 工具包
2016-06-08注意:本文仅适用于 nltk<3.2.5 及 2016-10-31 之前的 Stanford 工具包,在 nltk 3.2.5 及之后的版本中,StanfordSegmenter 等接口相当于已经被废弃,按照官方建议,应当转为使用 nltk.parse.CoreNLPParser 这个接口,详情见 wiki,感谢网友 Vicky Ding 指出问题所在。
NLTK 与 Stanford NLP
NLTK 是一款著名的 Python 自然语言处理(Natural Language Processing, NLP)工具包,在其收集的大量公开数据集、模型上提供了全面、易用的接口,涵盖了分词、词性标注(Part-Of-Speech tag, POS-tag)、命名实体识别(Named Entity Recognition, NER)、句法分析(Syntactic Parse)等各项 NLP 领域的功能。
Stanford NLP 是由斯坦福大学的 NLP 小组开源的 Java 实现的 NLP 工具包,同样对 NLP 领域的各个问题提供了解决办法。
斯坦福大学的 NLP 小组是世界知名的研究小组,如果能将 NLTK 和 Stanford NLP 这两个工具包结合起来使用,那自然是极好的!在 2004 年 Steve Bird 在 NLTK 中加上了对 Stanford NLP 工具包的支持,通过调用外部的 jar 文件来使用 Stanford NLP 工具包的功能。
从 NLTK 的 commit 历史中可以找到相应的提交记录:
commit e1372fef56bfb88d02fdb6c0ea88474d5f414a38 Author: Steven Bird <[email protected]> Date: Tue Aug 3 12:20:20 2004 +0000 added Stanford svn/trunk@2088
现在的 NLTK 中,通过封装提供了 Stanford NLP 中的以下几个功能:
- 分词
- 词性标注
- 命名实体识别
- 句法分析,依存句法分析
安装和配置
NLTK 3.2 之后加入了用于中文分词的 StanfordSegmenter 这个类,作者是知名 NLP 博主 52nlp,见 相关文章。而 NLTK 3.1 及之前则只有以下几个类:
- 分词: StanfordTokenizer
- 词性标注: StanfordPOSTagger
- 命名实体识别: StanfordNERTagger
- 句法分析: StanfordParser
- 依存句法分析: StanfordDependencyParser, StanfordNeuralDependencyParser
方便起见,本文以 NLTK 3.2 这个版本来说明如何进行相关的安装和配置,3.1 及之前的版本基本相同。
注意事项
需要注意这么几点:
- Stanford NLP 工具包自 2014 年 10 月后(大概是 version 3.5.0)需要 Java 8 及之后的版本,如果出错请检查 Java 版本
- 下面的配置过程都以 Stanford NLP 3.6.0 为例,如果使用的是其他版本,请注意替换相应的文件名
- 下面的配置过程以 NLTK 3.2 为例,如果使用 NLTK 3.1,需要注意该旧版本中 StanfordSegmenter 未实现,其余大致相同
下面的配置过程是针对不同的接口分别讲述各自如何配置,根据来自 NLTK 的源代码,分别是
- nltk/tokenize/stanford.py
- nltk/tag/stanford.py
- nltk/parse/stanford.py
如果不想了解这些细节,可以参考 NLTK 官方 wiki 页面上的内容,但需要注意的是,StanfordSegmenter 和 StanfordNeuralDependencyParser 这两者的配置和其他的都不一样,而 wiki 页面上并未覆盖到这部分内容。
- 事实上,也可以完全不进行环境变量设置,但这就需要在每次调用的时候手动指定参数
StanfordSegmenter
- 从 http://nlp.stanford.edu/software/segmenter.html 处下载 stanford-segmenter-2015-12-09.zip (version 3.6.0)
- 将 stanford-segmenter-2015-12-09.zip 解压, 并将解压目录中的 stanford-segmenter-3.6.0.jar 拷贝为 stanford-segmenter.jar
将 stanford-segmenter.jar 和 slf4j-api.jar 加入到 CLASSPATH 中去
例:
export STANFORD_SEGMENTER_PATH="$HOME/stanford/segmenter" export CLASSPATH="$CLASSPATH:$STANFORD_SEGMENTER_PATH/stanford-segmenter.jar:$STANFORD_SEGMENTER_PATH/slf4j-api.jar"
之所以要将 stanford-segmenter.jar 和 slf4j-api.jar 加入到 CLASSPATH 中,是因为在 StanfordSegmenter 的实现中显式依赖了这两个文件,并且优先在 CLASSPATH 中寻找这两个文件。如果在 CLASSPATH 中找不到 stanford-segmenter.jar ,则会在环境变量 STANFORD_SEGMENTER 指定的路径中寻找;同样的,如果找不到 slf4j-api.jar ,则会在环境变量 SLF4J 指定的路径中寻找。其他几个类也有同样的依赖设置,为了统一管理,可以将所有依赖的 jar 文件都加入到 CLASSPATH 中去,当然分别为不同的 jar 文件设置不同的环境变量也是可以的。
除了设置环境变量,也可以通过函数参数来传入依赖的 jar 文件的准确路径,此时将会忽略环境变量设置。
StanfordTokenizer
- 从 http://nlp.stanford.edu/software/tagger.html 中下载 stanford-postagger-full-2015-12-09.zip (version 3.6.0)
- 将 stanford-postagger-full-2015-12-09.zip 解压
将解压目录中的 stanford-postagger.jar 加入到 CLASSPATH 中,或者设置到环境变量 STANFORD_POSTAGGER 中
export STANFORD_POSTAGGER_PATH="$HOME/stanford/postagger" export CLASSPATH="$CLASSPATH:$STANFORD_POSTAGGER_PATH/stanford-postagger.jar"
或
export STANFORD_POSTAGGER="$HOME/stanford/postagger/stanford-postagger.jar"
StanfordNERTagger 和 StanfordPOSTagger
在 NLTK 里,StanfordNERTagger 和 StanfordPOSTagger 都继承自 StanfordTagger ,在设置上有共同之处,因此放到一起来讲一下。
- 从 http://nlp.stanford.edu/software/CRF-NER.html 处下载 stanford-ner-2015-12-09.zip (version 3.6.0)
- 从 http://nlp.stanford.edu/software/tagger.html 中下载 stanford-postagger-full-2015-12-09.zip (version 3.6.0)
- 将 stanford-ner-2015-12-09.zip 和 stanford-postagger-full-2015-12-09.zip 都解压
将解压后目录中的 stanford-ner.jar 和 stanford-postagger.jar 加入到 CLASSPATH 中去,和 StanfordTokenizer 不一样,这两个类都只从 CLASSPATH 中寻找对应的 jar 文件(所以为了统一我建议都添加到 CLASSPATH 中去)
export STANFORD_NER_PATH="$HOME/stanford/ner" export STANFORD_POSTAGGER_PATH="$HOME/stanford/postagger" export CLASSPATH="$CLASSPATH:$STANFORD_NER_PATH/stanford-ner.jar:$STANFORD_POSTAGGER_PATH/stanford-postagger.jar"
同时将 stanford-ner-2015-12-09.zip 解压后目录中的 classifiers 目录和 stanford-postagger-full-2015-12-09.zip 解压后目录中的 models 目录加入到环境变量 STANFORD_MODELS 中去
export STANFORD_MODELS="$STANFORD_NER_PATH/classifiers:$STANFORD_POSTAGGER_PATH/models"
StanfordParser, StanfordDependencyParser
StanfordParser 和 StanfordDependencyParser 都继承自 GenericStanfordParser ,使用 stanford-parser.jar 来提供句法分析功能。
- 从 http://nlp.stanford.edu/software/lex-parser.html 处下载 stanford-parser-full-2015-12-09.zip (version 3.6.0)
将下载的压缩包解压,并将其中的 stanford-parser.jar 和 stanford-parser-3.6.0-models.jar (这个在不同版本中名称会不一样) 都加入到 CLASSPATH 中
export STANFORD_PARSER_PATH="$HOME/stanford/parser" export CLASSPATH="$CLASSPATH:$STANFORD_PARSER_PATH/stanford-parser.jar:$STANFORD_PARSER_PATH/stanford-parser-3.6.0-models.jar"
或者将 stanford-parser.jar 加入到环境变量 STANFORD_PARSER 中,将 stanford-parser-3.6.0-models.jar 加入到环境变量 STANFORD_MODELS 中
export STANFORD_PARSER="$STANFORD_PARSER_PATH/stanford-parser.jar" export STANFORD_MODELS="$STANFORD_MODELS:$STANFORD_PARSER_PATH/stanford-parser-3.6.0.models.jar"
StanfordNeuralDependencyParser
StanfordNeuralDependencyParser 虽然也继承自 GenericStanfordParser,并且用来进行句法分析,但它使用的 Stanford CoreNLP 中的功能和模型,不依赖 Stanford Parser 这个(子)工具包。
- 从 http://stanfordnlp.github.io/CoreNLP/ 处下载 stanford-corenlp-full-2015-12-09.zip
将下载的压缩包解压,并将其中的 stanford-corenlp-3.6.0.jar 和 stanford-corenlp-3.6.0-models.jar 加入到 CLASSPATH 中去
export STANFORD_CORENLP_PATH="$HOME/stanford-corenlp-full-2015-12-09" export CLASSPATH="$CLASSPATH:$STANFORD_CORENLP_PATH/stanford-corenlp-3.6.0.jar:$STANFORD_CORENLP_PATH/stanford-corenlp-3.6.0-models.jar"
或者可以更简单地将解压目录设置为环境变量 STANFORD_CORENLP 的值
export STANFORD_CORENLP=$STANFORD_CORENLP_PATH
基本使用
使用 StanfordSegmenter 和 StanfordTokenizer 进行分词
StanfordSegmenter 是 52nlp 实现的对 Stanford Segmenter 的封装,用来进行中文分词。
# coding: utf-8 from nltk.tokenize import StanfordSegmenter segmenter = StanfordSegmenter( path_to_sihan_corpora_dict="/home/linusp/stanford/segmenter/data/", path_to_model="/home/linusp/stanford/segmenter/data/pku.gz", path_to_dict="/home/linusp/stanford/segmenter/data/dict-chris6.ser.gz" ) res = segmenter.segment(u"北海已成为中国对外开放中升起的一颗明星") print type(res) print res.encode('utf-8')
StanfordSegmenter 的初始化参数说明:
path_to_jar: 用来定位 stanford-segmenter.jar ,在设置了 CLASSPATH 的情况下,该参数可留空
注: 其他所有 Stanford NLP 接口都有 path_to_jar 这个参数,同样在设置了环境变量的情况下可以留空,后面不再另加说明。
- path_to_slf4j: 用来定位 slf4j-api.jar ,在设置了 CLASSPATH 或者 SLF4J 这个环境变量的情况下,该参数可留空
- path_to_sihan_corpora_dict: 设定为 stanford-segmenter-2015-12-09.zip 解压后目录中的 data 目录,话说这个参数名真是让人摸不着头脑
- path_to_model: 用来指定用于中文分词的模型,在 stanford-segmenter-2015-12-09 的 data 目录下,有两个可用模型 pkg.gz 和 ctb.gz
需要注意的是,使用 StanfordSegmenter 进行中文分词后,其返回结果并不是 list ,而是一个字符串,各个汉语词汇在其中被空格分隔开。
StanfordTokenizer 可以用来进行英文的分词,使用起来比较简单
# coding: utf-8 from nltk.tokenize import StanfordTokenizer tokenizer = StanfordTokenizer() sent = "Good muffins cost $3.88\nin New York. Please buy me\ntwo of them.\nThanks." print tokenizer.tokenize(sent)
使用 StanfordNERTagger 进行命名实体识别
所谓命名实体识别,是用来识别并标注文本中的人名、地名、组织机构名等单元,这些单元既是 "命名实体"。
# coding: utf-8 from nltk.tag import StanfordNERTagger eng_tagger = StanfordNERTagger('english.all.3class.distsim.crf.ser.gz') print eng_tagger.tag('Rami Eid is studying at Stony Brook University in NY'.split())
StanfordNERTagger 在初始化时需要指定所使用的模型,在 stanford-ner-2015-12-09.zip 解压后的 classifiers 目录中,有几个可用的英语 NER 模型:
/home/linusp/stanford/ner/classifiers/ ├── english.all.3class.distsim.crf.ser.gz ├── english.all.3class.distsim.prop ├── english.conll.4class.distsim.crf.ser.gz ├── english.conll.4class.distsim.prop ├── english.muc.7class.distsim.crf.ser.gz ├── english.muc.7class.distsim.prop ├── example.serialized.ncc.ncc.ser.gz └── example.serialized.ncc.prop
如果需要进行中文的命名实体识别,则可以在 Stanford Named Entity Recognizer 页面的 Models 一节找到中文模型的下载链接,下载得到 stanford-chinese-corenlp-2015-12-08-models.jar ,解压后将 edu/stanford/nlp/models/ner/ 目录下的 chinese.misc.distsim.crf.ser.gz 和 chinese.misc.distsim.prop 复制到模型目录下(stanford-ner-2015-12-09/classifiers)即可。
# coding: utf-8 from nltk.tag import StanfordNERTagger chi_tagger = StanfordNERTagger('chinese.misc.distsim.crf.ser.gz') sent = u'北海 已 成为 中国 对外开放 中 升起 的 一 颗 明星' for word, tag in chi_tagger.tag(sent.split()): print word.encode('utf-8'), tag
使用 StanfordPOSTagger 进行词性标注
所谓词性标注,是根据句子中的上下文信息,给句中每个词确定一个最为合适的词性标记,比如动词、名词、人称代词等。
和 StanfordNERTagger 一样,StanfordPOSTagger 需要的输入也是一个已经分好词的句子,下面是一个英文的词性标注实例:
from nltk.tag import StanfordPOSTagger eng_tagger = StanfordPOSTagger('english-bidirectional-distsim.tagger') print eng_tagger.tag('What is the airspeed of an unladen swallow ?'.split())
如果之前配置时下载的是 stanford-postagger-full-xxxx-xx-xx.zip ,在解压后,其中的 models 目录是包含有两个中文模型的,分别是 chinese-distsim.tagger 和 chinese-nodistsim.tagger ,可以直接使用。
# coding: utf-8 from nltk.tag import StanfordPOSTagger chi_tagger = StanfordPOSTagger('chinese-distsim.tagger') sent = u'北海 已 成为 中国 对外开放 中 升起 的 一 颗 明星' for _, word_and_tag in chi_tagger.tag(sent.split()): word, tag = word_and_tag.split('#') print word.encode('utf-8'), tag
这个中文的词性标注输出的结果有点奇怪……
使用 StanfordParser 进行句法分析
句法分析在分析单个词的词性的基础上,尝试分析词与词之间的关系,并用这种关系来表示句子的结构。实际上,句法结构可以分为两种,一种是短语结构,另一种是依存结构。前者按句子顺序来提取句法结构,后者则按词与词之间的句法关系来提取句子结构。这里说的句法分析得到的是短语结构。
from nltk.parse.stanford import StanfordParser eng_parser = StanfordParser(model_path=u'edu/stanford/nlp/models/lexparser/englishPCFG.ser.gz') print list(eng_parser.parse("the quick brown fox jumps over the lazy dog".split()))
得到的结果是一个 list, 其中的元素是 Tree 类型的,在上面这个例子中,这个 list 的长度是 1 ,调用 Tree 的 draw 方法可以将句法树绘制出来。
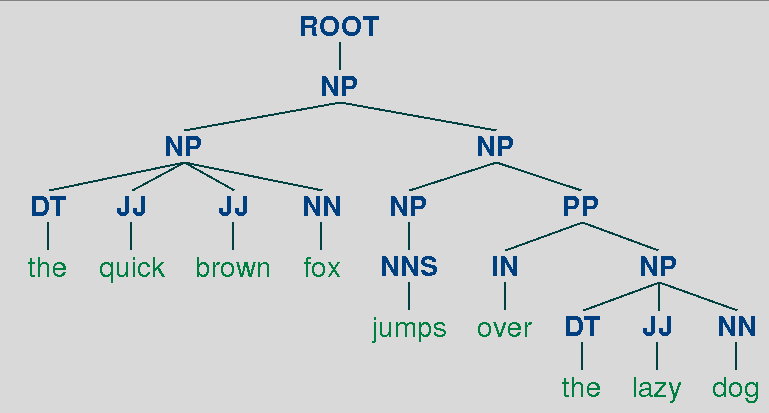
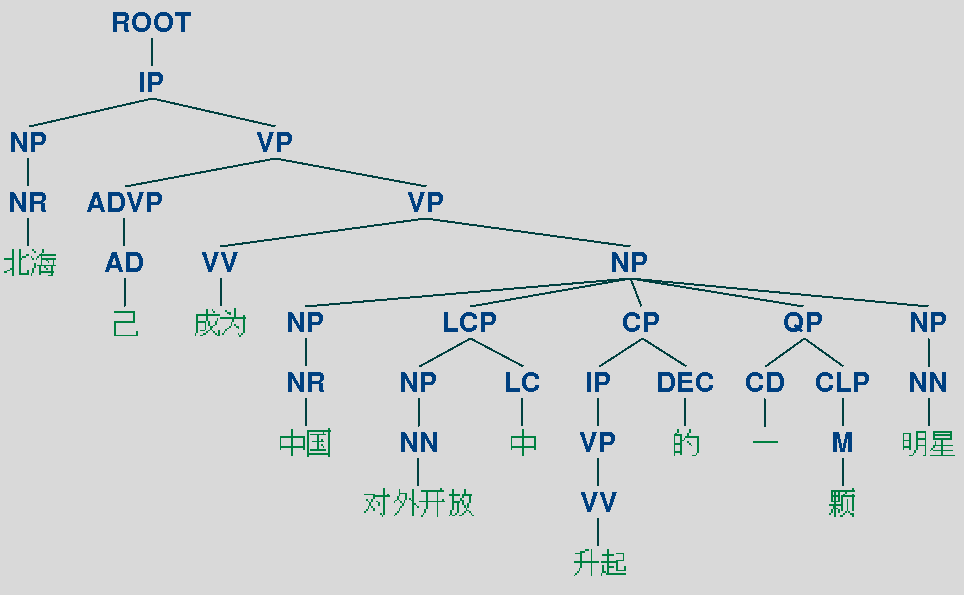
要进行中文的句法分析,只要指定好中文的模型就好,可用的中文模型有两个,分别是 'edu/stanford/nlp/models/lexparser/chinesePCFG.ser.gz' 和 'edu/stanford/nlp/models/lexparser/chineseFactored.ser.gz',依然拿 "_北海 已 成为 中国 对外开放 中 升起 的 一 颗 明星_" 这句话作为例子,得到的句法树如下所示。
使用 StanfordDependencyParser 进行依存句法分析
见上一节,依存句法分析得到的是句子的依存结构。
from nltk.parse.stanford import StanfordDependencyParser eng_parser = StanfordDependencyParser(model_path=u'edu/stanford/nlp/models/lexparser/englishPCFG.ser.gz') res = list(eng_parser.parse("the quick brown fox jumps over the lazy dog".split())) for row in res[0].triples(): print row
绘制出来的依存句法结构如下图所示。

中文的依存句法分析同理,在初始化时使用中文模型即可,不再赘述。
StanfordNeuralDependencyParser 的使用与 StanfordDependencyParser 一样,但是在本人的机器上执行非常耗时,即使是对一些简单句子,所以这里就不略过不讲了。