
自然语言处理与深度学习: 集智俱乐部活动笔记
2016-07-04目录
简介
本文为对 2016 年 7 月 3 日集智俱乐部活动「自然语言处理与深度学习」进行的总结。
集智俱乐部是张江在 2008 年建立的一个从事学术研究、享受科学乐趣的开放团体,它倡导以平等开放的态度、科学实证的精神,进行跨学科的研究与交流,力图搭建一个中国的 ”没有围墙的研究所”。我于 2014 年结缘集智俱乐部,从中结识到不少优秀又有趣的人。
集智会不定期地以读书会、讲座等形式进行线下活动,并且这两年的活动主要都聚焦于互联网和人工智能前沿技术上,7 月 3 日这期活动就是如此。
活动主讲人是是香港理工大学的在读博士李嫣然,其主要研究方向为自然语言的语义表达和语言生成。同时她还是微信公众号「程序媛的日常」的维护者之一小 S,这个公众号提供了高质量的关于机器学习和自然语言处理的文章,从事这方面工作或研究的朋友不妨关注一下。另,后文为了方便,一律用「小 S」来指代「李嫣然」。
下面是两个公众号的二维码,有兴趣的可以关注一下:
| 集智俱乐部 | 程序媛的日常 |
|---|---|
 |
 |
自然语言处理的基本任务
自然语言是我们日常用于互相沟通的最常见方式,结合个人的观点以及小 S 讲述的内容,「用自然语言进行沟通」可以分解为以下几个步骤:
- 对于接收到的信息,判断是否是自然语言
- 在确定接收到自然语言数据后,对其进行理解
- 在理解接收的自然语言数据后,组织好要回复的内容并将其传达给另一方

好好好,我说人话,别打脸!
场景一: 接收到非自然语言
—— 小明: 汪汪汪汪喵喵喵 —— 小红: (说人话,不然滚犊子)
场景二: 接收到自然语言,但理解不能
—— 小明: 苟利国家生死已,岂因祸福避趋之,小红你有没有一种钦定的感觉? —— 小红: (这个人在说什么……)
场景三: 接收到自然语言,理解并回复
—— 小红: 小明,下午放学后你把教室的窗户玻璃擦一擦吧! —— 小明: 我擦,我不擦!
小 S 将这个过程划分为 Perceive、Understand 和 Communicate 三部分,并为 NLP 主要的研究或应用方向和这三部分进行对应,如下图所示:
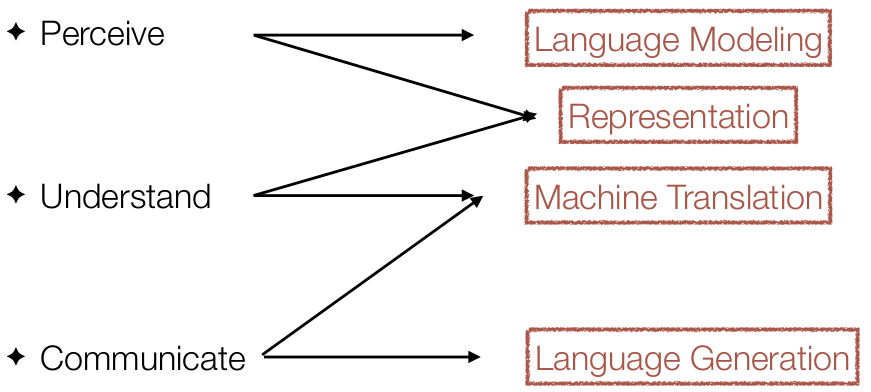
Perceive、Understand 和 Communicate 和我之前总结的那三个步骤一一对应,或者说,之前我所说的那三个步骤,是我对 Perceive、Understand 和 Communicate 的理解吧。
- Language Modeling: 对语言的建模是对整个语言或者特定场景下的语言的特性的一个刻画,所得到的结果通常被称之为「语言模型(Language Model, LM)」
- Representation: 所谓表示一般是对具体的文本的语义、语法上的刻画,比如一个具体的词、一个具体的句子等等
- Machine Translation: 机器翻译,无须多说
- Language Generation: 即根据语义、语法生成有符合自然语言语法并能表达正确语义的文本
语言建模用来刻画整个语言的特性,所得到的语言模型有很多的应用,其中之一就是用来计算某个「给定句子」在这个语言的出现的概率以判别这个句子是不是一个「合理」的句子。而具体的词和句子等元素的表示,一方面是能用来分析这些元素的语义,另一方面也还反映了其所属语言的一些特性,因而是与 Perceive 和 Understand 都相关。
Language Generation 则是在理解之后进行的结果的组织,组织成自然语言当然是要给人看的,这是它和 Communicate 之间的关系所在。Machine Translation 作为一个重要的 NLP 应用方向,需要确保源语言句子和目标语言句子具备同样的语义,从目的上来说本身就是为了提高人与人之间的沟通效率的,因此和 Understand、Communicate 的关系也是很明白的。
对语言进行建模的若干方法
语言模型简介
语言模型是对语言整体特性的一个刻画,理想情况下,我们当然希望这个模型能够完全刻画「语言整体」,但有几个问题:
- 从时间角度来看,语言整体一直是在变化的,我们无法建立一个能刻画过去、现在和未来所有时刻语言特性的模型,因此一般的做法是对某个时段的语言数据进行采样
- 从语言本身来看,在不同的场景、人群中,同一种语言,其特性也会稍有不同,我们也无法建立一个能刻画所有可能的子语言特性的模型,尽管有人为建立「通用语言模型」而努力,但这种通用性本身也是相对的,绝对通用的语言模型不存在。换言之,在进行语言数据的采样时,按自己的需要,可能还需要将采样范围限制在某些特定的场景或人群中
按上述两个条件得到的语言数据,被称之为「语料(Corpus)」,理想的情况下,我们希望:
- 语料中不同时间的语言数据的特性基本稳定
- 在限制在特定场景或人群中时,希望数据能尽量涵盖受限条件下语言的各种情况
第一点要求语料的质量,第二点要求语料的规模,但实际情况中这两者很难一起得到保证。
有了语料后,我们怎么去得到语言模型呢?换言之,所谓的「特性」该如何量化?
首先,我们要知道,这个语言模型都涵盖了哪些基本元素,所谓「基本元素」,以英文为例,一般是单词,当然实际上也可以是词组或者字符,但单词是我们认识语言(至少是英文)的比较基本的单元。
然后呢,对任意的这些基本元素组成的序列,一般来说,就是句子,这个模型能给出其置信度(Confidence),用来判断这个句子在这个语言下的合理性,通常表现为一个概率。在语音识别以及其他一些应用中,通常会在最后有若干个候选的句子结果,此时就要用置信度来从中选择最合理的结果。比如说下面两个句子,他们的发音基本上是一样的,但我们是可以知道第一个句子其实是更合理的。
- It's hard to recognize speech
- It's hard to wreck a nice beach
总结一下,从给定的语料中可以得到一个语言模型,语言模型包含两部分:
- 包含语料中出现的基本元素的一个有限集合: \(V = \{ e_{1},e_{2}, ..., e_{n} \}\)
- 一个概率分布,对给定的序列 \(W = w_{1}w_{2}...w_{m}\),可以得到概率 \(P(W)\),其中 \(w_{i} \in V\)
也许我们会想,是不是需要考虑语法结构?毕竟一个合理的句子,应该是大致符合自然语言的语法结构的,但首先我们的自然语言并没有一个精确的、无歧义的语法规则,其次语法规则本身已经是一个更高抽象级别的概念了 —— 简单的就是好的,我们更愿意去寻找一些简单的方法,N-gram 语言模型和神经网络语言模型(Neural Network Language Model, NNLM)就是这样。
N-gram 语言模型
基于马尔可夫假设,我们可以认为,在句子中每个「基本元素」出现的概率只和其前面的元素有关,这样,对给定句子 \(W=w_{1}w_{2}...w_{m}\),可以得到其概率为:
\[P(W) = P(w_{1})\cdot P(w_{2}|w_{1})\cdot P(w_{3}|w_{1}w_{2})... P(w_{m}|w_{1}w_{2}...w_{m-1})\]
但是这样的条件概率仍然难以计算,因此我们再进一步地假设: 每个「基本元素」只和其前面 \(N-1\) 个元素有关。在这样的假设即 N-1 阶马尔可夫假设下,前面的式子可以进行近似简化(以 \(N=3\) 为例):
\[\begin{eqnarray} P(W) &=& P(w_{1})\cdot P(w_{2}|w_{1})\cdot P(w_{3}|w_{1}w_{2})\cdot P(w_{4}|w_{1}w_{2}w_{3})... P(w_{m}|w_{1}w_{2}...w_{m-1}) \\ &\approx& P(w_{1})\cdot P(w_{2}|w_{1})\cdot P(w_{3}|w_{1}w_{2})\cdot P(w_{4}|w_{2}w_{3})... P(w_{m}|w_{m-2}w_{m-1})) \end{eqnarray}\]
这样我们就得到了一个 3 阶的「N-gram 语言模型」,又称「Trigram 语言模型」,相应的,1 阶 N-gram 语言模型被称为「Unigram 语言模型」,2 阶 N-gram 语言模型被称为「Bigram 语言模型」,4 阶语言模型则可以简称为「4-gram 语言模型」,依次类推。除了能得到我们期望的概率分布外,大于 1 阶的 N-gram 语言模型还隐式地通过上下文信息一定程度上反映了语言的语法结构。
这里的「gram」是一个抽象的概念,在不同的粒度下它可以对应不同的单元,比如说我们如果基于字符来建模,这个 gram 就是字符;如果基于词来建模,这个 gram 就是词。一般情况下我们使用词作为 gram ,后文一些示例或讨论,如无特殊说明,默认使用词作为 gram。
根据上面的式子,我们要做的,就是从语料中得到每个「N-gram」的概率,最简单的办法是用「极大似然估计(Maximum Likelihood Estimation, MLE)」—— 即直接统计每个 N-gram 的在语料中的频次然后除以频次之和作为概率值。
from __future__ import division from collections import Counter def build_ngram(corpus, gram_level): """ :param corpus: list of sentence :param gram_level: as it says """ freqs = Counter() for sentence in corpus: seq = sentence.strip().split() for index in xrange(len(seq) - gram_level + 1): gram = tuple(seq[index:index+gram_level]) freqs[gram] += 1 total_count = sum(freqs.itervalues()) return {gram: freq / total_count for gram, freq in freqs.iteritems()}
但这样的简单的计算方式是有问题的,在实际应用中,往往因为语料的规模不够,导致一些低频的 N-gram 在语料中未出现,这样在计算句子概率的时候,一个概率为 0 的 N-gram 将导致整个句子的概率为 0,此即「零概率问题」。随着 N 的增大,这个问题会越发的明显。
零概率问题的解决办法是将语料中一些有的 N-gram 的频次「分」一点给这些未出现的 N-gram,这个叫 「折扣(discount)」;或者用这个未出现的 N-gram 的低阶形式的概率来估计,这个叫做「backoff」。这些方法统称为「平滑(smoothing)」方法。
基于神经网络的语言模型
Bengio 在 2003 年提出的神经概率语言模型(Neural Probabilistic Language Model, NPLM)是影响较大的基于神经网络的语言模型1。其模型思想其实和 N-gram 语言模型还是同出一源,即基于 N-1 阶马尔可夫假设,认为句子中某个词是由其前面的 N-1 个词决定的。模型使用的网络结构如下图所示。
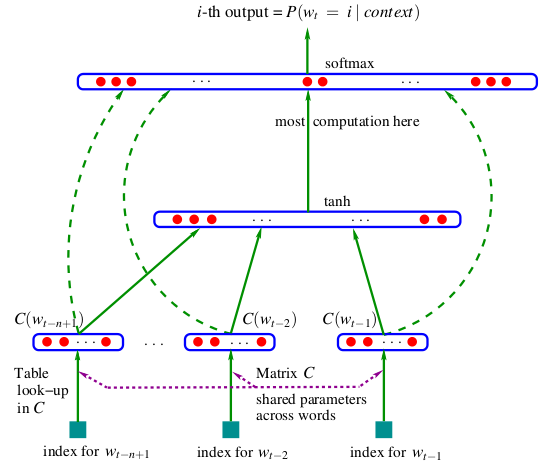
这个模型将 N-1 个词的表示拼接起来作为输入,然后去预测下一个词最有可能是哪个。输出层会是一个很大的向量,每一维的值就是每一个可能的词的条件概率,这样要计算一个句子的概率也就没问题了。
这样基于神经网络的语言模型有什么好处呢?
- N-gram 需要显式存储每个 N-gram 的内容和概率,于是模型体积会随着语料的扩充而膨胀,但 NPLM 没有这个问题
- N-gram 需要应用各种平滑方法来解决零概率问题,但 NPLM 不存在这个问题,即使是语料中没出现的 N-gram ,依然能给出非 0 的概率值
- 模型中会学习一个固定长度的向量来表示一个词,且向量中各维度的值都是连续实值而非离散的 0/1 ,此即「Word Embedding」的较早形式
Bengio 还在论文中提到可以用「循环神经网络(Recurrent Neural Network, RNN)」来减少模型参数数量和捕获更远距离的上下文信息(longer term context),这些观点无疑是非常具有前瞻性的。
当然,值得一提的是,现为「IDL 杰出科学家」的徐伟曾在 2000 年独立提出用神经网络构建 Bigram 语言模型的思路2。
在这之后,Tomas Mikolov 于 2010 年提出基于 RNN 的语言模型(Recurrent Neural Network Language Model, RNNLM)3,并且顺着这个方向一直发论文发到博士毕业,Bengio 还是厉害啊 —— 话说 Google Scholar 上 Tomas Mikolov 的照片一头长发害近视眼的我以为他是个姑娘呢 :)
RNNLM 的根本思想和 NPLM 是共通的,不同的地方在于词是逐个输入到模型中的,然后隐藏层有一个具有「记忆功能」的单元将之前的词的信息都记录了下来,然后在输出层去预测下一个词。如果把其中的记忆单元拿掉就变成了一个学习 Bigram 语言模型的前馈神经网络了。
语言的表示方法
在 NLP 的应用场景里,无论我们是要做分类、聚类、摘要、机器翻译,首先我们要将要处理的具体文本转换成模型能够处理的数学形式,并且要求这种表示能够反映文本的独特信息。这就是所谓「Representation」,其实也就是特征提取了。
说 representation 是 NLP 的核心应该不为过吧,事实上在其他机器学习相关的领域,特征表达都是非常重要的,特征设计、特征筛选在以前甚至现在依然是非常重要的一个学术和应用问题。
词的表示: one-hot 与 embedding
单个字符因为不具有语义,所以一般不对其表示方法作过多探讨(暂不考虑汉语)。词作为我们认识语言的基本单元,表示它们的最简单方法,就是为词进行编号,比如说我有一个包含 1 万个词的词典,第一个词就记为「1」,第二个记为「2」,依次类推。
这样当然是可以的,在一些简单的任务,比如文本分类上,问题不大,比如说我们可以统计不同 id 的词在两个文本中出现的频次来判断两个文本的相似程度。但问题在于 id 是一个类别变量值,它的值是不能用于比较、不能用于计算的,假想一下我们要构造一个简单的 NNLM ,某次输入的 N-gram 中包含了 id 为 10000 的词,如果直接输入到模型中,这个巨大的值会导致网络产生严重的偏差。
为了解决这个问题,我们一般用所谓「one-hot representation」来表示一个词,具体做法是,每个词都表示为一个向量,这个向量只有一个维度的值为 1,其他维度的值全为 0,且不同词值为 1 的维度都不同。比如说我们要处理的问题中只包含 5 个词,将这 5 个词编号后,可以分别表示为:
第一个词: [1 0 0 0 0] 第二个词: [0 1 0 0 0] 第三个词: [0 0 1 0 0] 第四个词: [0 0 0 1 0] 第四个词: [0 0 0 0 1]
这就是 one-hot 的含义所在,每个词的向量表示中,只有一个位置是「激活的」。
one-hot 表示应用广泛,但它本身有几个问题:
- 数据稀疏,一个包含 10000 个词的问题,每个词都要表示为长度 10000 的向量,但只有一个位置是有值的,这将会造成很大的存储开销
- 缺乏语义信息,两个词之间无法进行相似性比较
2003 年 Bengio 提出 NPLM 的时候,在模型中去学习每个词的一个连续向量表示,并经过 Tomas Mikolov 等人的发展4,发展出「Word Embedding」这一表示方法。比如说前面那五个词的表示,用 word embedding 表示后,可能是这样子的:
第一个词: [0.2 0.3 0.5] 第二个词: [0.7 0.1 0.2] 第三个词: [0.1 0.2 0.3] 第四个词: [0.2 0.3 0.4] 第四个词: [0.3 0.4 0.6]
这样两个词之间就可以比较了——当然,这种表示下相似值高的两个词,并不一定是具有相同语义的,它只能反映两者经常在相近的上下文环境中出现。但无论如何,one-hot 表示的两大问题,word embedding 都给出了一个解决方案。
word embedding 反映的词与词之间的相似性,可能在语义层面并不能说是真正的相似(取决于如何定义「相似」了),但「两个 word embedding 接近的词,它们是相关的」这一点是毋庸置疑的,如下图所示。
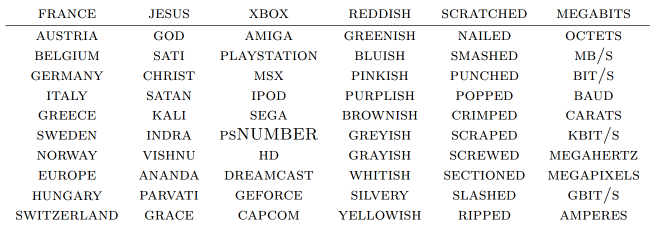
除了能反映同一语言的词之间的关系之外,不同语言之间语义近似或相关的词的 word embedding 也将这种关系反映了出来。
此外,word embedding 还能一定程度上反映语言的内在规律(linguistic regularity),比如说 'king - man + woman = queen' 之类的,当然这个特定在实际应用场景里是很少用到的,而且我没记错的话主题模型也可以做到类似的事情,所以也并不是什么新东西了。
以上都是从 word embedding 本身来看的一些特点,但根据后来的一些讨论,word embedding 所反映的「相似性」其实要在具体的应用场景下才有确切的意义,像上面提到的 multi-lingual 的相似甚至 multi-modal 的相似,以及 linguistic regularity ,在实际应用中使用得还是较少的。引用小 S 的话,word embedding 更大的意义在于「它已经成为了各种后续或者更高级别粒度的语言表达的基础,这是完全超出相似度的一件事,也是词向量带来的最大贡献」。
当然除了 one-hot 和 word embedding 外,也还有其他的一些特征表示方法,比如说词性、语法结构等信息,都可以附加到词的特征上去。
更深入的关于 word embedding 的讨论,推荐这篇文章: “后 Word Embedding” 的热点会在哪里?
句子及更高层级数据的表示: VSM 和 embedding
句子、段落和文章,我们都可以把它们视为是词的序列,因此在很多场景下可以用统一的方式来进行表示。当然,在涉及句法结构分析时,基本是以句子为单位的,这里暂时不考虑这种情况。作为词的序列,我们该如何去表示它们呢?理想情况下当然是希望词的顺序啊、语义啊、语法结构啊都能够表达出来,但如果要将这些都反映出来,所使用的特征会比较复杂,光是语义和语法结构就够我们喝一壶了。
在文本分类、文本相似度量等一些主要的应用场景中,我们使用向量空间模型(Vector Space Model, VSM)来表示一段文本。VSM 经常和词袋模型(Bag Of Words, BOW)联系在一起。而 BOW 假设词和词之间是互相独立的,认为词和词之间的位置信息是不重要的,可以算作是 VSM 的一个前提、假设。
BOW 的解释也很形象,它假想我们有一个袋子,每遇到一个词就将其丢进袋子中,直到处理完所有文本。在此基础上, VSM 要求用一个向量来表示各个文档,这个向量的长度要与词袋中不同的词的数量一致。比如说我们有下面两段文本:
(1) John likes to watch movies. Mary likes movies too. (2) John also likes to watch football games.
那么我们得到的词袋中包含的词就是 (John, likes, to, watch, movies, also, football, games, Mary, too) 共 10 个词,这样两段文本可以分别表示为:
(1) [1, 2, 1, 1, 2, 0, 0, 0, 1, 1] (2) [1, 1, 1, 1, 0, 1, 1, 1, 0, 0]
如上所示,不同位置的值为对应的词在文本中的权重,这里使用的是词频。这样两段文本之间的相似程度可以简单地通过算余弦距离来得到。当然在实际中,我们希望不同维度的值是能反映对应的词在文本中的「重要程度」的,而直接使用词频并不能达到这个目的,事实上有一些常用的词会在很多的文本里都具有较高的频次,但它们本身并不包含重要的信息。所以一般用 TF-IDF(词频-逆文档频率)来作为词的权重。
VSM 的一个问题是,其特征表示往往会很稀疏(想象一个包含了 100,000 个不同词汇的文本集合),解决这个问题的一个方法是将一些文档频率很高的词去除,因为这样的词不能为文本与文本之间的区分性作出贡献,这样的方法能有效地降低向量的维度并保留有效的信息。
VSM 的另外一个问题是缺乏语义信息。比如说下面两个句子,它们表达的意义是不一样的,但在 VSM 中,两者的表示会一模一样
(1) Mary loves John (2) John loves Mary
这个问题的一个解决办法是使用 N-gram 而非 word 来作为基本单元,比如用 Bigram,上述两句话得到的词袋会是: (Mary loves, loves John, John loves, loves Mary),对应的,两个句子可以表示为:
(1) [1, 1, 0, 0] (2) [0, 0, 1, 1]
另外一个办法就是,使用句子级别的 embedding 表示。常用的方法有 RNN 和 CNN 两种。
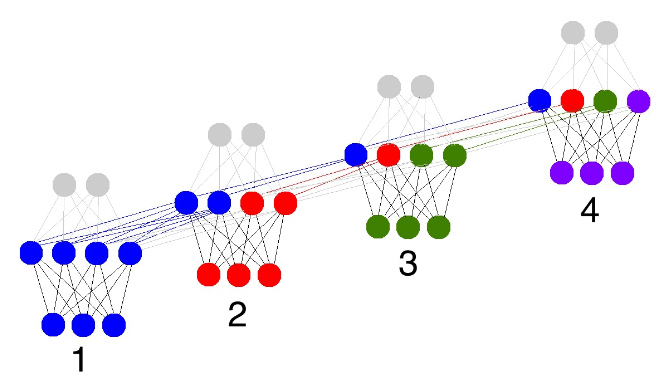
RNN 的话比较简单,将句子中的词逐个输入到模型中,结束时取隐藏层的输出即可。这是因为 RNN 隐藏层的输出是由之前的「记忆」和当前的输入计算得到的,可以认为是「整个句子的记忆」,也就是一个句子的特征表示了。如下图所示:
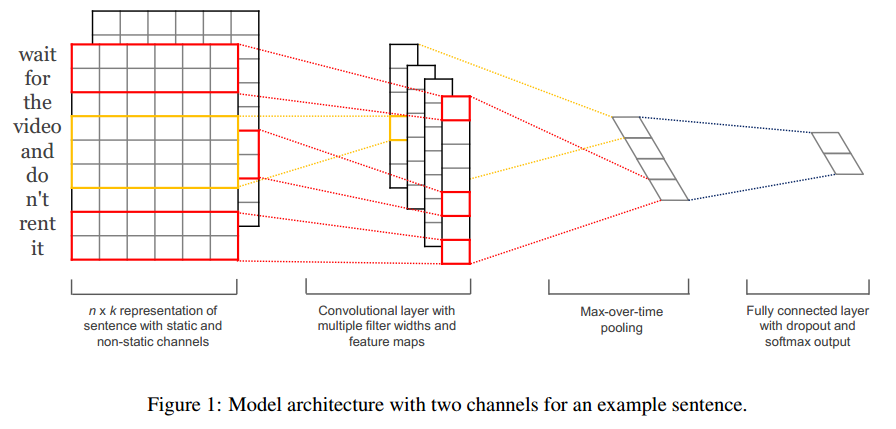
CNN 的话是将句子中的词的向量表示拼接成一个矩阵,然后在上面进行卷积,最后得到一个向量表示,如下图所示:
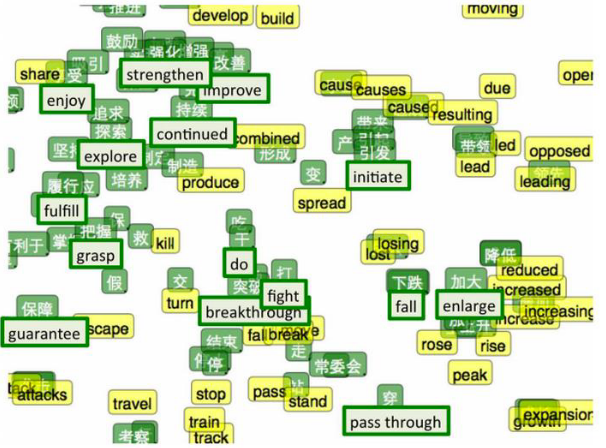
CNN 和 RNN 得到的 sentence embedding,同 word embedding 一样,可以进行相似性的对比,语义相近的句子,其向量表示在空间中也会比较接近,如下图所示:

所以,既然可以得到 sentence embedding,能不能得到 paragraph embedding 乃至 document embedding 呢?对于前者,Tomas Mikolov 在 2014 年提出了「Paragraph Vector」5,后者的话似乎还没见到过。在 Mikolov 的实验中,paragraph vector 在情感分析上和信息检索两个任务上都取得了比其他模型更好的结果。不过和 word embedding 一样,sentence embedding 和 paragraph embedding 的可解释性仍然存在问题。
机器翻译: 从 SMT 到 end-to-end
沟通是人类的本能,所以将一种语言翻译成另外一种语言的需求,早在 17 世纪就有人提出来了,但我相信在更早之前,在不同语言的人群交界的地方,就已经有人在尝试做这个事情了。不过直到 1903 年,「机器翻译」这个词才被正式提出来。
1953 年的时候,Weaver 等人发表了一篇名为《Translation》的文章6,并在其中提出两个基本的思想:
- 翻译类似于密码解读的过程
- 原文与译文表达的是相同的意思,翻译可以通过将源语言转换成一个「通用语言」,然后再转换为目标语言
这里提到的「通用语言」是一种虚构的语言,假定为全人类共同的。这个思想其实和后面要讲到的 Encoder-Decoder 的思想有一些共通之处呢!
从方法上来说,最早使用的是基于规则的方法,后面出现了基于实例的方法,然后在大概 1999 年,在 IBM 推出了 5 种「基于词的统计翻译模型」并取得非常好的成绩后,统计机器翻译(Statistical Machine Translation, SMT)成为了机器翻译的主流方法,直到现在依然如此,Google、Bing、百度等几家的在线翻译系统,都是基于统计方法的。
统计机器翻译(Statistical Machine Translation, SMT)
目前主流的机器翻译系统,其基本思想来源于「噪声信道模型」,即认为源语言的句子 \(f\) 是目标语言 \(e\) 经过含噪声的信道编码后得到的,翻译的过程就是要求解出 \(\hat{e}\)
\[\hat{e} = \mathop{arg\,max}_{e}p(e|f)\]
然后利用贝叶斯公式,转换为
\[\hat{e} = \mathop{arg\,max}_{e}p(f|e)p(e)\]
其中 \(p(f|e)\) 被称为「翻译模型」,\(p(e)\) 则是语言模型。后者可以通过收集目标语言的语料训练得到,但前者怎么办呢?一个简单的思路是,将源语言句子中的每个词都翻译成目标语言对应的词,然后通过重新排列这些词得到符合目标语言语法的句子 —— 后面这个过程称为「词对齐(word alignment)」。
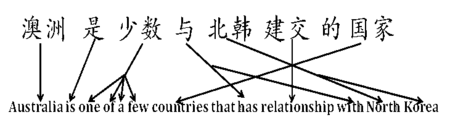
所以翻译模型会由两部分组成,一部分是词到词的映射,另一部分是对结果进行对齐。整个系统要在所有可能的对齐结果中找到最好的那个。
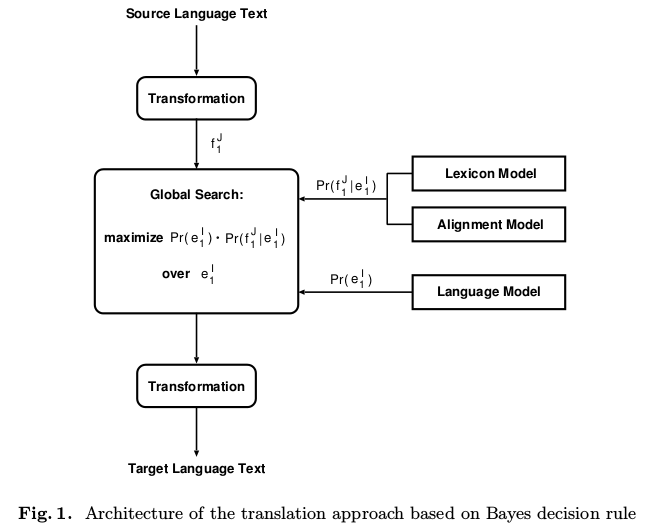
这就是传统的统计机器翻译模型的基本原理。
端到端(end-to-end)的新方法
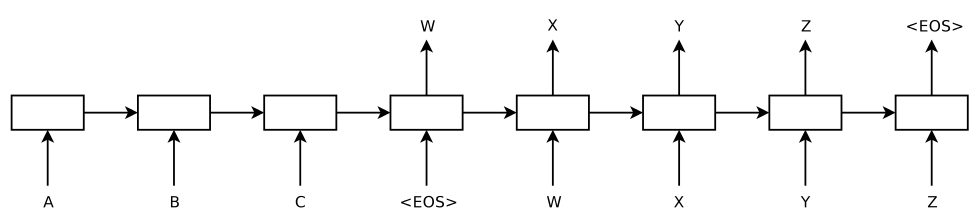
2014 年的时候,Kyunghyun Cho7 和 Sutskever8 先后提出了一种 End-to-End 即所谓「端到端」的模型,在英语到法语的翻译实验上取得了很好的成绩,前者将其模型命名为 Encoder-Decoder 模型,后者则将其命名为 Sequence-to-Sequence 模型,不过两者其实在结构上基本是一样的。其核心思想都是:
- 将输入的句子经过一个 RNN 生成一个能反映句子语义的向量,类似计算 sentence embedding 的过程,
- 用另一个 RNN ,从输入句子的向量表达中解码出另一个句子
第一个过程称之为 encoding,第二个过程称之为 decoding,整个模型非常的简单优雅,不需要词对齐,不需要额外的语言模型,输入英语,直接得到法语,这就是所谓「端到端」。
Encoder-Decoder 模型虽然在结构上很简单,但它有很重要的两个特点:
- 大部分序列到序列的预测问题,都可以使用该模型,这个序列甚至没有必要是文本,语音、图像同样可以
- 先 encoding 再 decoding 的 encoder-decoder 的结构,可以推广到非 RNN 的模型上去
当然,虽然 encoder-decoder 的模型结构简单优美,在一些问题上也还不错,它仍然是有缺点的,回到机器翻译问题上来,将一个句子 encode 成一个向量,真的是合适的么?一方面这个过程相当于进行数据压缩,肯定是会有信息损耗的,而且这种损耗随着句子长度的提高会越来越大;另一方面,翻译的时候并不一定需要完全理解整个句子的含义后才能进行,比如可能在看完句子的前半部分以后就可以进行部分的翻译,每个翻译结果中的词的生成都使用整个句子的语义的话,无疑准确度也会受到限制。
在这之后,Dzmitry Bahdanau 在 encoder-decoder 模型的基础上增加 attention 机制来解决这个问题9,通过双向 RNN 来在 decoder 时得到不同时刻的上下文信息。
其中 decoder 在每一个 time step 用下面的式子计算条件概率以判断该输出什么词。
\[p(y_{i}|y_{1}, ..., y_{i-1}, x) = g(y_{i-1}, s_{i}, c_{i})\]
其中 \(s_{i}\) 是 decoder 的隐藏状态
\[s_{i}=f(s_{i-1}, y_{i-1}, c_{i})\]
而 \(c_{i}\) 则是根据从 encoder 中不同时刻的隐藏状态得到的上下文信息,用来决定输出时该聚焦于输入序列的哪些部分。
\[c_{i}=\sum_{j=1}^{T_{x}}\alpha_{ij}h_{j}\]
上式中的 \(\alpha_{ij}\) 构成的权值矩阵就是最核心的内容,将其可视化的话,能发现高亮的部分其实相当于是源语言句子和目标语言句子之间的对齐路径
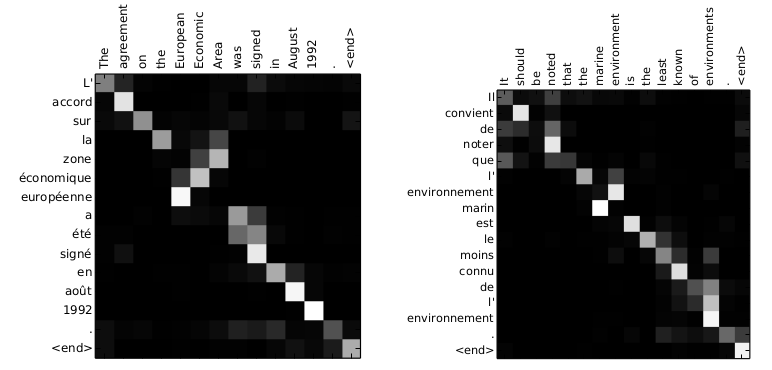
对照传统的统计机器翻译系统,在 encoder-decoder 模型中,模型本身相当于隐含了语言模型和词到词翻译的两个部分,但却缺乏词对齐部分,而 attention 机制的加入弥补了这个缺陷。
另外要说的是,attention 机制和 encoder-decoder 一样,更大意义上在于它提供了一种解决问题的思路,而不是说某个具体的模型结构,事实上 attention 机制的实现是多种多样的,不一定要使用 RNN。在应用上,attention 机制在图像、视频上也有很大的应用空间,比如在目标识别时用来聚焦于不同的图像区域。

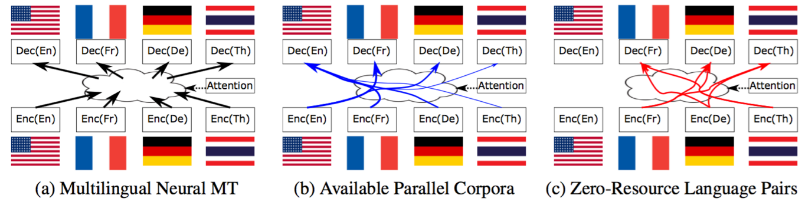
2016 年, Kyunghyun Cho 又提出结合了 encoder-decoder 和 attention 的多语言翻译模型10,能够接收多用语言的输入,并翻译成多种不同的语言。
自然语言生成(Natural Language Generation, NLG)
从模板方法到 encoder-decoder
说到自然语言生成,我的第一反应是大刘的《诗云》,以及他制作的一款名为「电子诗人」的自动作诗软件。来看一看用电子诗人生成的一首「现代诗」:
作品第75509号——
我面对着黑色的艺术家和荆棘丛生的波浪
我看到,剌眼的心灵在午睡,程序代码在猛击着操场
在这橄榄绿的操场中,没有货车,只有蝴蝶
我想吸毒,我想软弱地变黄
我面对着光灿灿的冬雪和双曲线形的霞光
我看到,青色的乳房在漂荡,肥皂在聆听着海象
在这弱小的春雨中,没有贝多芬,只有母亲
我想上升,我想呼吸着歌唱
我面对着宽大的小船和透明的微波束
我看到,枯死的渔船在叫,蒸馏水在铲起羊
在这多孔的青苔中,没有夏娃,只有老师
我想冬眠,我想可恶地发光
我面对着多血的史诗和悠远的大火
我看到,生机勃勃的战舰在沉默,透明裙在爱抚着操场
在这曲线形的奋斗者中,没有月光舞会,只有风沙 我想摆动,我想粗糙地惊慌
自然语言生成除了上述这种娱乐性质的作用外,目前在自动天气预报、机器翻译、Image Caption 和对话系统中都有应用。
说到自然语言生成,如果要我们自己实现的话,能很快想到的一个基础的办法,就是模板生成方法。在一些受限环境下,需要返回的文本形式可能比较简单,用模板方法还是可以取得能用的结果的。

不过模板方法的缺点也是显而易见的:
- 泛化性极低,换一个场景就要重新设计一个不同的模板,如果要进行通用领域的自然语言生成,模板数量将会多到爆炸
- 输出非常死板僵硬,如果是在对话这样的场景下,用户很快就会发现得到的文本是由机器生成的
- 并没有真正「理解文本」
怎么样才算是理想的「自然语言生成」呢?
Once aware of the communicative goals, machines can understand the meaning of the content (what is important, what is what), and automatically generate natural, meaningful and plausible language. —— By 小 S
几个重点是:
- 理解得到的输入(根据不同的场景,可能是文本会图像)
- 要生成自然的语言表达,就算是胡说八道,也要一本正经
对于一本正经地胡说八道这件事情,其实是可以用语言模型来,用 N-gram 模型的话,随机选一个词,然后找到关联的概率最高的几个 N-gram ,依次类推。另外一种办法是在已有特定语言的「基本句法规则」的情况下,先生成句法结构,然后往里面填充词语。当然,这两种方法都是很简单的,如果直接使用的话生成的文本其实本身没有什么意义,要放到具体的应用场景里的话,这样的方法还必须和其他一些方法结合才行。
而使用之前提到的 encoder-decoder 框架,在一些场景下,能够做到 end-to-end 的生成,比如 Image Caption。
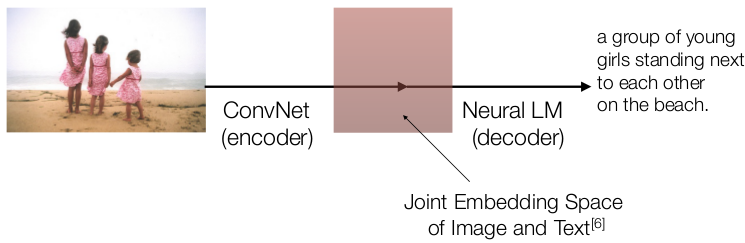
所以说 encoder-decoder 这个想法真的是非常好用的呀!
对话系统中的自然语言生成
对话系统中使用到的技术,大致上可以分成三部分:
- 基于知识库的检索方法
- 基于知识图谱的简单推理
- 基于生成模型的自然语言生成方法
第一部分是在知识库中直接找到「合适的」现成的文本返回给用户,和自然语言生成基本没什么关系;第二部分涉及到对用户意图的分析,可能会有一些基于模板、规则的生成过程;第三部分,据我所知,好几家做问答的公司,都在尝试用 encoder-decoder 的模型。
没做过问答,以上都是我瞎编的 :)
前两部分就不谈了,第三部分使用 encoder-decoder 模型,基本都是基于 RNN 来去实现。这种生成模型虽然能够「理解」用户的问题并且一本正经的胡说八道,但仍然存在一些需要解决的问题。
- 语义漂移(semantic drift),直观点来说就是答非所问
- 生成的文本在语法上有时并不符合自然语言特性(这真是在胡说八道了……)
- 训练语料中的高频句式会频繁出现,典型的如「万能回复」问题,其实也算是语义漂移的一个表现
- 生成的文本语言风格可能与实际场景不符合
本质上 encoder-decoder 也可以认为是一种检索办法,只不过相比基于知识库的检索方法,它是一种模糊的、更细粒度的检索,语义漂移的问题其实就是模型在其巨大的解空间中迷路了,要解决这个问题,一方面是提高方向感,一方面也可以将解空间进行限制。Google 的 Allo 就被设计成使用混合响应策略来解决这个问题。
所谓的「混合响应策略」,其实就是通过其他的方法来辅助咯,比如获取用户的个人信息作为辅助特征,比如通过知识图谱并将推理结果输入到模型中,再比如确定用户的地理位置和环境因素作为额外的特征。
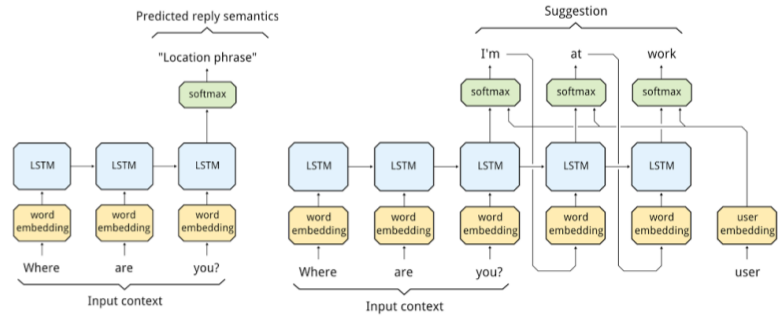
至于语言风格的问题,可以通过情感分析等手段来获取用户的情绪状态,然后输入到模型中以得到不同风格的响应。
此外,在对话系统中,一个很典型的问题是「多轮对话问题」—— 大部分对话系统都是「一问一答」的,很少考虑前几轮对话的内容,也就是我们常说的「上下文」。对于这个问题,小 S 的回答是,目前在一块的研究中提到的方法大概有这么几种:
- 将前几轮的历史对话信息作为额外的输入
- 设计多层次的对话系统
- 结合用户画像(user profile)来生成文本,取 top-5 的答案再进一步筛选
综上,encoder-decoder 模型虽然简单强大,但仍然有自身固有的问题,如果要设计一个良好的对话系统,以目前的情况,还是需要和传统方法进行结合。
后记
这应该是我参加集智的活动之中质量最高的一次了,75 页的 slides,覆盖 NLP 几大基本问题的内容和展开,加上小 S 本身在 NLP 这块的造诣,给我带来了很大的收获。又因为自己对 NLP 兴趣浓厚,参加完活动后就兴起了写一个完整笔记的念头,历时五天,查阅了很多的论文,把个中尚未明白的一些细节搞清楚,总算是完成了这篇 1 万多字的笔记。
希望以后能看到更多这样高质量的活动!
脚注:
Bengio, Yoshua, et al. "A neural probabilistic language model." journal of machine learning research 3.Feb (2003): 1137-1155.
Xu, Wei, and Alexander I. Rudnicky. "Can artificial neural networks learn language models?." (2000).
Mikolov, Tomas, et al. "Recurrent neural network based language model." Interspeech. Vol. 2. 2010.
Mikolov, Tomas, et al. "Distributed representations of words and phrases and their compositionality." Advances in neural information processing systems. 2013.
Le, Quoc V., and Tomas Mikolov. "Distributed Representations of Sentences and Documents." ICML. Vol. 14. 2014.
Weaver, Warren. "Translation." Machine translation of languages 14 (1955): 15-23.
Sutskever, Ilya, Oriol Vinyals, and Quoc V. Le. "Sequence to sequence learning with neural networks." Advances in neural information processing systems. 2014.
Cho, Kyunghyun, et al. "Learning phrase representations using RNN encoder-decoder for statistical machine translation." arXiv preprint arXiv:1406.1078 (2014).
Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. "Neural machine translation by jointly learning to align and translate." arXiv preprint arXiv:1409.0473 (2014).
Firat, Orhan, Kyunghyun Cho, and Yoshua Bengio. "Multi-way, multilingual neural machine translation with a shared attention mechanism." arXiv preprint arXiv:1601.01073 (2016).