
论文笔记:Visualization Analysis for Recurrent Networks
2018-11-10简介
这篇论文是清华大学语音和语言技术中心(Center for Speech and Language Technologies, CSLT)2016 年的一篇论文,不过奇怪的是在 Google Scholar 上找了一圈,给出的引用链接竟然是 CSLT 的 wiki 链接,难道是没有正式发表的一篇论文吗?
这篇论文主要从从近年来 LSTM 在 ASR 中的优异表现出发,用一些可视化方法,希望能深入理解这种有效性是如何产生的,非常有意思。这方面相关的工作有
- 2013 年的《Training and analysing deep recurrent neural networks》
- 2014 年的《Empirical evaluation of gated recurrent neural networks on sequence modeling》
- 2015 年的《LSTM: A search space odyssey》
- 2015 年 Andrej Karpathy 的《Visualizing and understanding recurrent networks》
- 2015 年的《Visualizing and understanding neural models in nlp》
- 2016 年的《Representation of linguistic form and function in recurrent neural networks》
- 2016 年的《Simplifying long short-term memory acoustic models for fast training and decoding》
后续这些论文的笔记我也会补充上来。
实验和结论
首先论文用 LSTM 和 GRU 分别在华尔街日报(Wall Street Journal, WSJ)数据集上进行对比,结果显示在 ASR 任务上,GRU 的效果要比 LSTM 稍好,至于为什么会更好,则在后面的实验中进行了可能的探讨。
Activation patterns
接着,在已经训练好的 ASR 模型上,输入 500 条音频数据,然后在网络的各层中随机挑选 50 个神经元,观察这些神经元的 cell value 的分布情况。
在基于 LSTM 的模型上,1-4 层的 cell value 分布情况如下图所示:
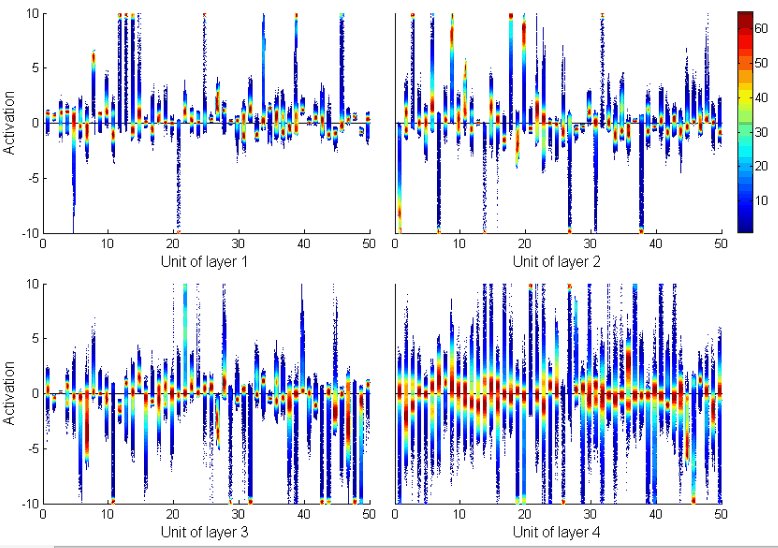
可以看到,在 LSTM 上,cell value 基本上分布在 [-10, 10] 这个区间,且在 0 附近比较密集,而这种密集程度在更高的层级上慢慢降低。
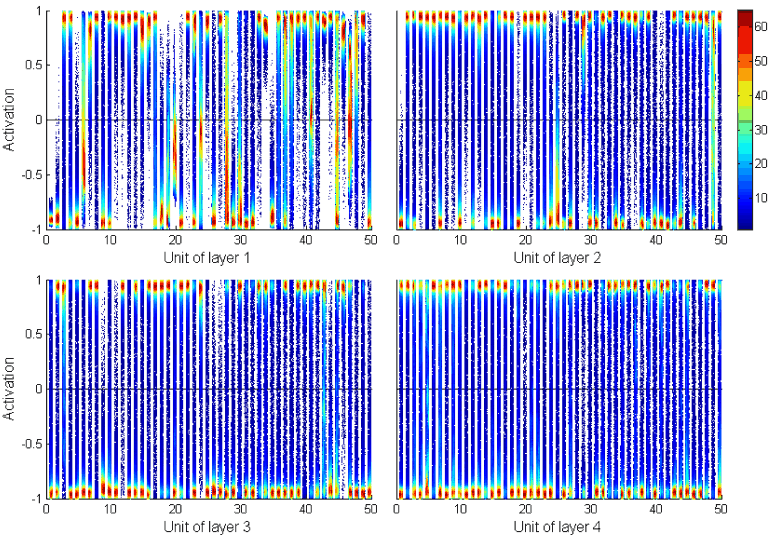
而 GRU 的情况则很是不同,cell value 分布在 [-1,1] 这个区间中,然后在边界(即-1 和 1处)上比较密集,并且随层级变高而更加集中。如下图所示:
通过下面的图则能更直接地看到,LSTM 中的大部分 cell value 都在 (-2, 2) 区间上,而 GRU 中大部分 cell value 都在 [-1, -0.7] 和 [0.7, 1] 中。
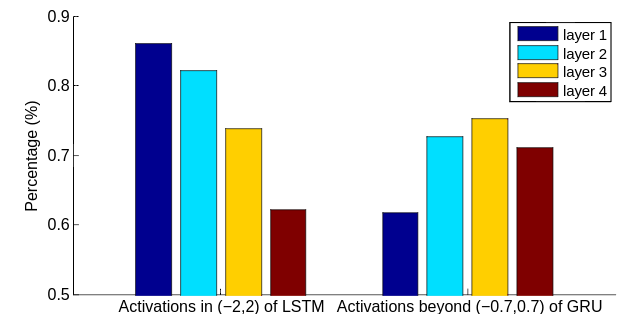
当然 GRU 的 cell value 分布在 [-1, 1] 这个区间是可以直接通过 GRU 的计算式推导出来的,只要 cell value 的初始值是 [-1, 1] 内的值,后面 cell value 的新值都会严格地被限制在 [-1, 1] 这个区间。
论文对 LSTM 和 GRU在这点上的差异,作出如下结论:
- LSTM relies on greatpositive or negative cell values of some units to represent information.
- GRU relies on the contrast among cell values of different units to encode information.
- This difference in activationpatterns suggests that information in GRU is more distributed than in LSTM.
- this may lead to a more compact model with a better parameter sharing(in GRU)
Neuronal Responsibility
第二个可视化实验稍微复杂一些。首先要为一个神经元定义一个叫做 responsibility 的东西,这个 responsibility 指一个神经元对一个音素的 cell value 是 irregular 的概率,而所谓 irregular ,在 LSTM 上是至 cell value 超出 (-10, 10) 这个区间,在 GRU 上则指 cell value 包含在区间 (-0.5, 0.5) 之中。刚才的实验也说明了,神经元的 cell value,大部分都是 regular(和刚才的 irregular 对应)的,那么如果某个神经元对某个音素经常产生 irregular 的响应,这就说明这个神经元对这个音素很敏感,也就是说,它能识别出这个音素来。这个实验就是以此为出发点来进行的。
在有上述定义后,统计 LSTM 各层对各个音素的 responsibility 超过 80% 的神经元数量,如下图所示:
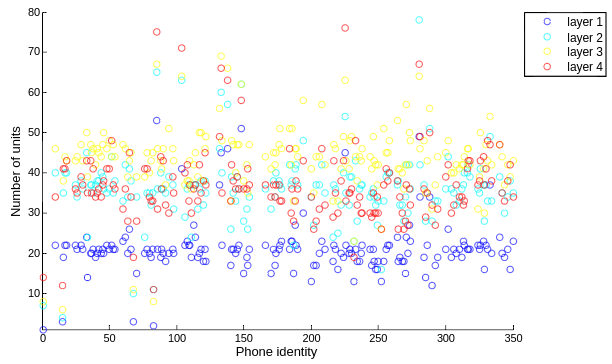
统计 GRU 各层对各个音素的 responsibility 超过 50% 的 unit 数量,如下图所示。
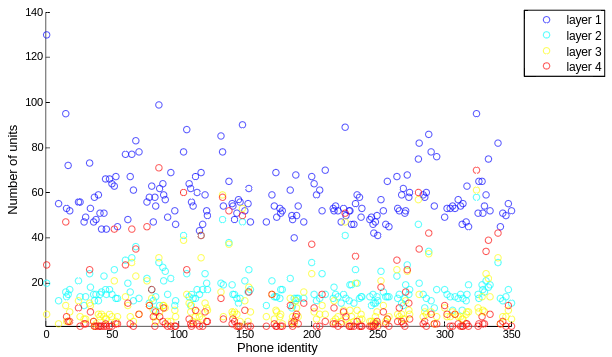
首先,两者都有一个共性,那就是同一层上,对某个音素的 responsibility 超过 80% 的神经元数量基本一样;区别是,在 LSTM 上,随着层数变高,对音素的 responsibility 超过 80% 的神经元总体呈现变多的趋势,而且会对某些个特别的音素的特别多;而 GRU 上层数变高,responsibility 超过 80% 的神经元在变少,也有对某些音素 responsibility 超过 80% 的神经元,但相对少一些。
LSTM 在高层倾向于识别更多的音素,而 GRU 则相反倾向于只对少数音素作出响应。这种差异作何解释有待进一步讨论。
就这个实验的出发点来说,在我看起来,应该是可以用统计物理学上的能量函数来作解释。
Temporal Trace
第三个可视化实验也挺有意思,它将基于 LSTM 或 GRU 的 ASR 模型识别一条音频数据时的 cell vector 的连续变化情况记录下来,并用 t-SNE 降维后做可视化。结果如下图所示:
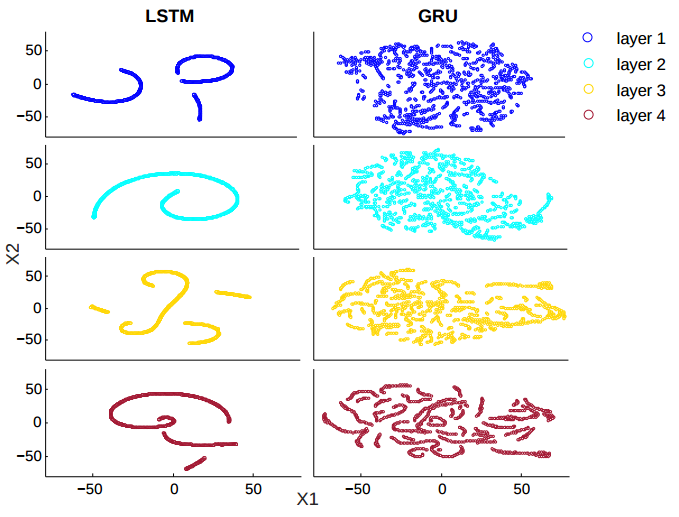
可以看到 LSTM 再次和 GRU 产生了区别。LSTM 的每层的轨迹大体上都是连续平滑的,论文里的解释是说 LSTM 能记得更多的东西,因此当前的输出会很大地受到过去记忆的影响,被平均后就变得平滑;而与此对比的 GRU,则倾向于给予新的数据更大的权重,换言之遗忘地会更快,因此在前几层的时候,轨迹变化地会更剧烈一些。
另外一个不同是,GRU 的轨迹在高层后慢慢地也变得连续了,这就说明 GRU 的底层是倾向于记忆新的输入,但在高层则倾向于把旧的记忆也融合进来。这就很有意思了。
Memory robustness
这个实验是为了比较 LSTM 和 GRU 的抗噪能力,方法也很简单,就是在输入数据的前部插入一些噪声数据,然后和正常的数据对比,观察网络中神经元的 cell value 的差异,结果如下图所示:
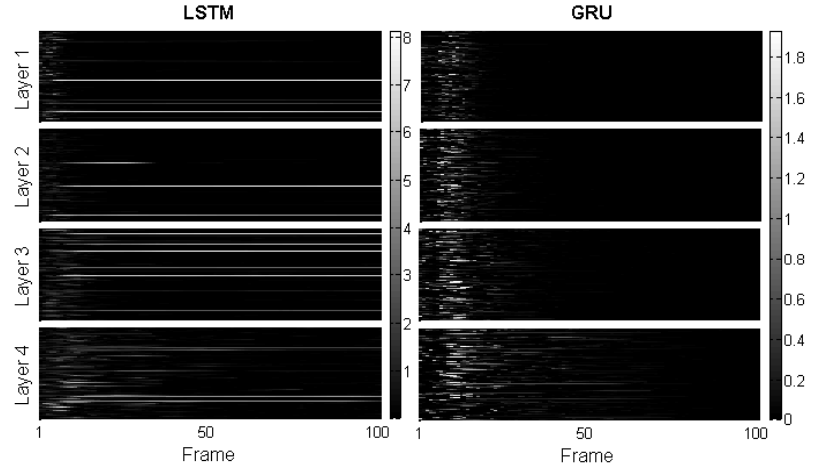
可以看到 LSTM 中噪声的影响会长时间地持续下去,而在 GRU 中这种噪声的影响会比较快地被消除掉。也就是说 GRU 更鲁棒,从另外一方面来说,也可以认为 GRU 能记忆的东西更少,倾向于记忆新的输入,因而遗忘地更快,于是噪声数据产生的干扰就在后面被抹除了。
Application to structure design
在论文的最后,作者根据前几个实验得到的结论,尝试对 LSTM 作出一些调整。第一个调整是把 cell state 的更新操作放到计算输出之后,像 GRU 一样,并称这个特性为「lazy cell update」。结果显示这样修改后,LSTM 在 WSJ 数据集上的效果稍有提升并和 GRU 接近了。
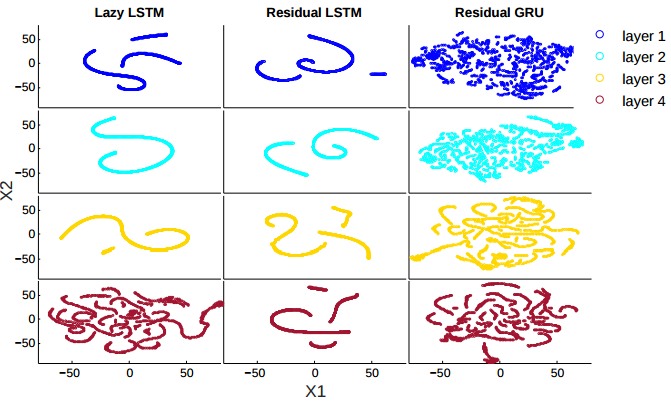
有意思的一个现象是在这样修改后,LSTM 高层的 temporal trace 变得更碎更不平滑了,接近 GRU 的情况。这就说明前面的一些差异,很可能是和 LSTM 与 GRU 更新 cell state 的顺序差异造成的,从计算式上来看似乎也说得通。
此外作者还尝试在 LSTM/GRU 上加上 residual learning,效果也稍有提升。但是这个我持保留态度。
此外比较遗憾的一点是,作者虽然尝试修改 LSTM 让 cell state 的更新延后,却没有尝试对 GRU 作出相反的修改也就是让 GRU 的 cell state 的更新提前。我的想法是这样修改后再去做对比,如果得到的结论和修改 LSTM 的结论一致,就更能说明问题了。