
图数据库 Neo4j 的部署、数据导入和简单使用
2019-04-30目录
本文介绍了 Neo4j Server 的不同部署方式,并以豆瓣电影图谱数据为例说明了不同的数据导入方式,并简单介绍了 Cypher 查询语言的使用。
Neo4j 简介

Neo4j 是一个流行的、Java 编写的图数据库 —— 所谓图数据库是一种 NoSQL 数据库,相比于 MySQL 之类的关系数据库(RDBMS),能更灵活地表示数据,这种灵活性体现在多方面:
- 像所有 NoSQL 数据库一样可以灵活地设计、扩展 schema
- 更适合表示实体之间的关系,特别是当实体之间存在大量的、复杂的关系的时候
图数据库强调实体和关系两个基本概念,虽然说在关系数据库中也可以表示实体和关系,但如果关系的种类繁多且实体之间通过关系构成复杂的结构的时候,用图数据库可能会更合适一些。此外,图数据库会对一些常见的图操作进行支持,典型的比如查询最短路径,如果用关系数据库来做就很比较麻烦。
目前的图数据库有很多种,根据一些排行数据,Neo4j 应该是其中最流行、使用最多的了。
Neo4j 由一个商业公司在开发、维护,并提供 GPLv3 协议的开源社区版本,当然相比他们商业授权的闭源版本,开源版本缺少一些特性,但基本功能都是完整的。
Neo4j 的部署
最简单的办法是从 Neo4j 的下载中心下载 Neo4j Server,解压后运行即可。可以看到下载页有三个不同的版本
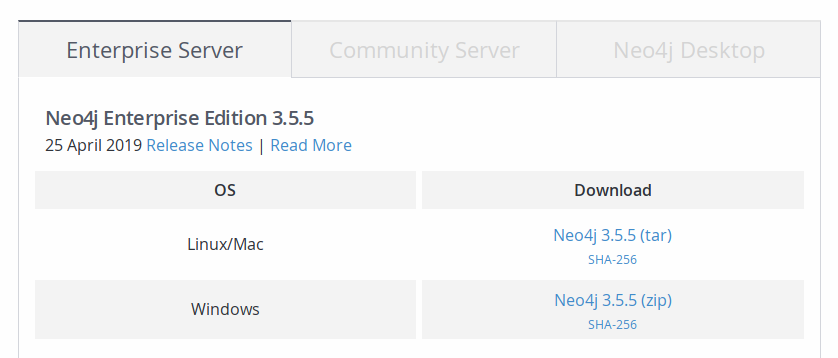
- Enterprise Server: 企业版,需要付费获得授权,提供高可用、热备份等特性
- Community Server: 社区开源版,只能单点运行,在性能上较企业版可能差一些
- Neo4j Desktop: 顾名思义,是一个桌面版的客户端,可以用其连接 Neo4j Server 进行操作、管理,不过其中也内置了一个本地的 Neo4j Server,用户可以直接通过 Neo4j Desktop 来创建数据库并启动
对于仅仅想了解一下 Neo4j 的人来说,不妨下载 Neo4j Desktop 体验一下,本文则仅讨论 Neo4j Community Server。
目前 Neo4j Server 的版本是 3.5.x,虽然更旧的版本也能用,但建议使用 3.5.0 之后的版本,因为更早的版本是不支持全文索引的。
以 Linux 为例,假如下载的是最新的 3.5.5 版本,那么解压运行即可
我的做法是解压放到 /opt 目录下,并把对应的目录加到环境变量 PATH 里
tar xzvf neo4j-community-3.5.5-unix.tar.gz mv neo4j-community-3.5.5 /opt/neo4j/ export PATH=$PATH:/opt/neo4j/bin
这样之后就能使用 neo4j start 来启动服务了。
另外一种办法是通过 docker 来启动服务,这个就更简单了,直接利用官方提供的镜像即可。
docker pull neo4j:3.5.5 mkdir $HOME/neo4j/data -p docker run -p 7474:7474 -p 7687:7687 -v $HOME/neo4j/data/:/data neo4j
这之后就可以通过 http://localhost:7474/browser/ 这个地址访问 Neo4j Server 的 WebUI,可以在上面查询、修改数据。
然后有一些 Server 设置,可以根据自己的情况适当地进行修改,完整的配置见文档,这里罗列一些个人认为重要的
认证方式设置
默认情况下启动的 neo4j,会要求在访问时通过用户名密码进行认证,初始的用户名密码为 neo4j/neo4j ,但是会在第一次认证之后要求更换密码,有点不太方便。
一个办法是彻底关闭用户名密码认证,如果是非 docker 模式部署的,直接改 /opt/neo4j/conf/neo4j.conf 这个文件,加上这行配置
dbms.security.auth_enabled=false如果是 docker 模式部署的,则在启动容器时,设置环境变量
NEO4J_AUTH为 nonedocker run -p 7474:7474 \ -p 7687:7687 \ -v $HOME/neo4j/data/:/data \ -e NEO4J_AUTH=none \ neo4j
另外一个办法是主动设置好密码,如果是非 docker 模式部署,需要在初次启动通过
neo4j-admin这个命令来设置neo4j-admin set-initial-password neo4j_password
如果是 docker 模式部署,则在启动容器时通过环境变量
NEO4J_AUTH来设置docker run -p 7474:7474 \ -p 7687:7687 \ -v $HOME/neo4j/data/:/data \ -e NEO4J_AUTH=neo4j/neo4j_password \ neo4j
内存设置
这块有三项设置,分别是
- dbms.memory.heap.initial_size
- dbms.memory.heap.max_size
- dbms.memory.pagecache.size
前两者决定了查询语言运行时候可用的内存,第三个则用于缓存数据和索引以提高查询效率。
非 docker 模式部署的,可以直接在 /opt/neo4j/conf/neo4j.conf 里修改,比如说这样
dbms.memory.heap.initial_size=1G dbms.memory.heap.max_size=2G dbms.memory.pagecache.size=4G
docker 模式部署则还是在启动容器时通过环境变量来设置,如下所示
docker run -p 7474:7474 \ -p 7687:7687 \ -v $HOME/neo4j/data/:/data \ -e NEO4j_dbms_memory_heap_initial__size=1G \ -e NEO4j_dbms_memory_heap_max__size=2G \ -e NEO4j_dbms_memory_pagecache_size=4G \ neo4j
- 其他
dbms.security.allow_csv_import_from_file_urls
设置为 true,这样在执行
LOAD CSV语句时,可以使用远程而非本地的 csv 文件。docker 的话这样:
docker run -d -p 7474:7474 \ -p 7687:7687 \ -e NEO4J_dbms_security_allow__csv__import__from__file__urls=true \ -v /home/emonster/data/neo4j/:/data \ neo4j
这个之后会具体再聊一下。
dbms.connectors.default_listen_address
这个不设置的话,部署起来的 server 就只能监听本地的请求,如果是在生产中用 Neo4j Server 的话,要设置成
dbms.connectors.default_listen_address=0.0.0.0
docker 的话默认已经设置好了,不用自己再单独设置。
所有的配置项及其值可以用如下查询语言查询
call dbms.listConfig()
如果要查询单独某项的值,比如 "dbms.connectors.default_listen_address",则这样
call dbms.listConfig("dbms.connectors.default_listen_address")
数据加载
为方便说明,我准备了一份豆瓣电影的图谱数据(说是图谱其实结构很简单)放在 Github 上,可以先将其 clone 到本地
git clone https://github.com/Linusp/kg-example
在这个项目下的 movie 目录里有按照 Neo4j 支持的格式整理好的实体、关系数据
(shell) $ cd kg-example (shell) $ tree movie movie ├── actor.csv ├── composer.csv ├── Country.csv ├── director.csv ├── district.csv ├── Movie.csv └── Person.csv 0 directories, 7 files
上述数据包含三类实体数据:
| 实体类型 | 数据文件 | 数量 | 说明 |
|---|---|---|---|
| Movie | Movie.csv | 4587 | 电影实体 |
| Person | Person.csv | 22937 | 人员实体 |
| Country | Country.csv | 84 | 国家实体 |
此外还包含四类关系数据
| 关系类型 | 主语实体类型 | 宾语实体类型 | 数据文件 | 数量 | 说明 |
|---|---|---|---|---|---|
| actor | Movie | Person | actor.csv | 35257 | 电影的主演 |
| composer | Movie | Person | composer.csv | 8345 | 电影的编剧 |
| director | Movie | Person | director.csv | 5015 | 电影的导演 |
| district | Movie | Country | district.csv | 6227 | 电影的制片国家/地区 |
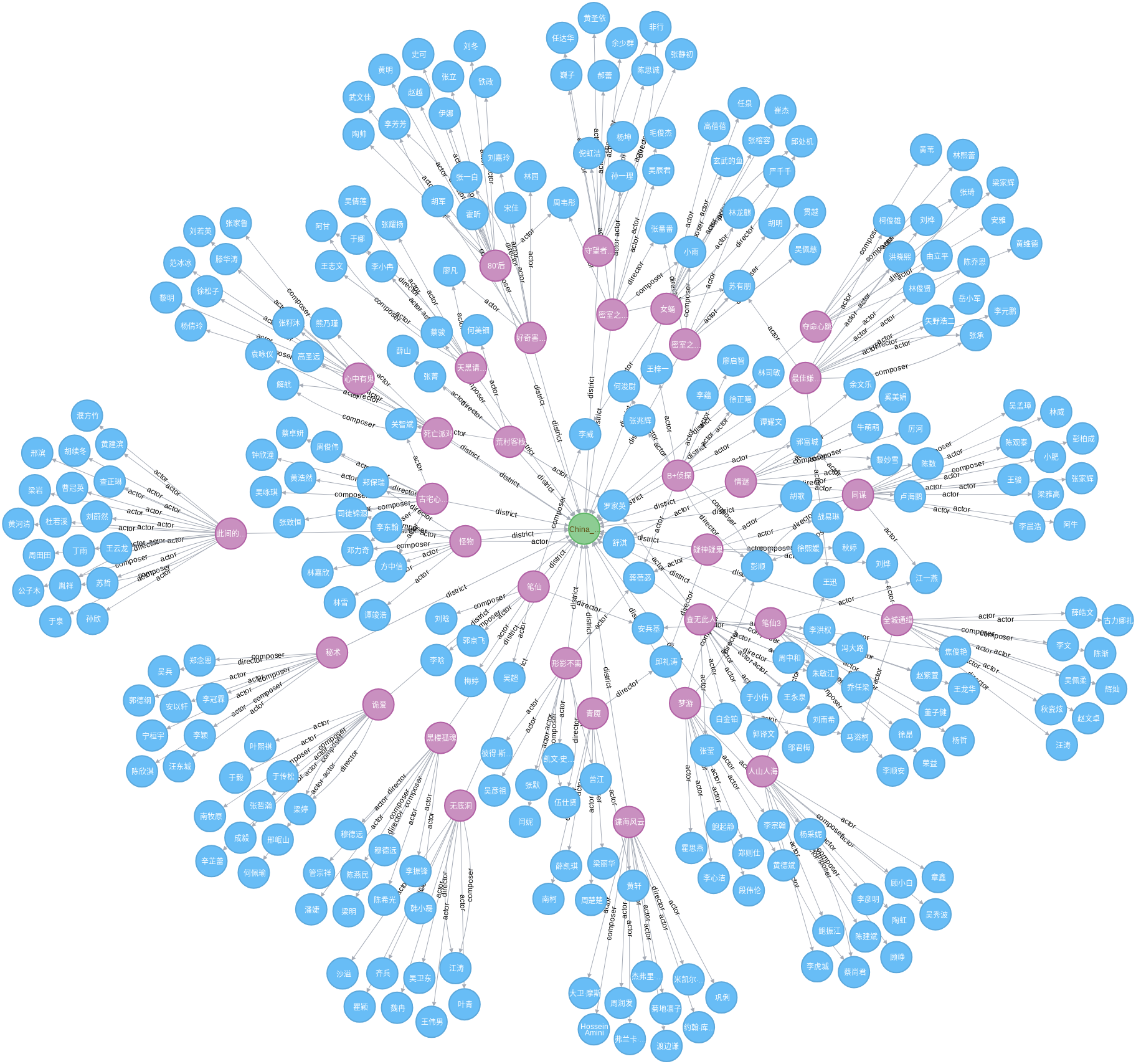
下图是这份数据加载到 Neo4j 后的部分可视化示例
使用 neo4j-import 用 csv 数据创建实体和关系
使用 neo4j-import 命令行工具导入 csv 数据是几种数据加载方式中最快的一种,但它不能导入数据到已有的数据库中,每次执行都是产生一个全新的数据库,因此必须在一条命令里将数据库中要包含的数据全部都制定好。
可以用下面的命令来导入豆瓣电影图谱数据
neo4j-import --into graph.db --id-type string \ --nodes:Person movie/Person.csv \ --nodes:Movie movie/Movie.csv \ --nodes:Country movie/Country.csv \ --relationships:actor movie/actor.csv \ --relationships:composer movie/composer.csv \ --relationships:director movie/director.csv \ --relationships:district movie/district.csv
上述命令会在当前目录下生成一个 graph.db 目录,就是最终产生的一个全新的数据库。要启用这个数据库,必须将其放置到 Neo4j Server 的 data 目录下:
如果当前 Neo4j Server 正在运行,需要先停掉它
neo4j stop
删除或备份原有的数据库
mv /opt/neo4j/data/databases/graph.db /opt/neo4j/data/databases/graph.db.bak
将产生的 graph.db 放置到 server 的 data 目录下
cp graph.db /opt/neo4j/data/databases/ -r
重新启动 Neo4j Server
neo4j start
实体和关系一共 8 万多条,在我的个人电脑上一共花费 3s 多
IMPORT DONE in 3s 692ms. Imported: 27608 nodes 54844 relationships 91628 properties Peak memory usage: 524.24 MB
如果是以 docker 的方式来使用 Neo4j,则稍有不同,需要在执行的时候将 movie 目录和输出结果所在的目录都挂载到容器里。假设说我们希望最终输出结果到 $HOME/neo4j/data 目录下,那么,先创建这个目录
mkdir $HOME/neo4j/data/databases -p
然后执行
docker run -v $PWD/movie:/movie:ro -v $HOME/neo4j/data:/data/ \ neo4j neo4j-import --into /data/databases/graph.db --id-type string \ --nodes:Person /movie/Person.csv \ --nodes:Movie /movie/Movie.csv \ --nodes:Country /movie/Country.csv \ --relationships:actor /movie/actor.csv \ --relationships:composer /movie/composer.csv \ --relationships:director /movie/director.csv \ --relationships:district /movie/district.csv
然后再用 docker 启动 Neo4j Server,并让其使用刚刚产生的数据库
docker run -p 7474:7474 \ -p 7687:7687 \ -v $HOME/neo4j/data/:/data \ -e NEO4J_AUTH=neo4j/neo4j_password \ neo4j
使用 LOAD CSV 加载 csv 数据
用 LOAD CSV 语句同样可以加载 csv 数据,不过和 neo4j-import 不一样,本质上它只是负责从 csv 文件中读取数据,如果要将读取到的数据写入到数据库中,还必须通过 CREATE 语句。也正因如此,用 LOAD CSV 语句来加载数据,不需要将 Neo4j Server 停掉。
用 LOAD CSV 语句将豆瓣电影图谱加载到数据库中的做法是下面这样的
从 Movie.csv 中加载电影数据并创建 Movie 实体
USING PERIODIC COMMIT 1000 LOAD CSV with headers from 'https://raw.githubusercontent.com/Linusp/kg-example/master/movie/Movie.csv' as line CREATE (:Movie { id:line["id:ID"], title:line["title"], url:line["url"], cover:line["cover"], rate:line["rate"], category:split(line["category:String[]"], ";"), language:split(line["language:String[]"], ";"), showtime:line["showtime"], length:line["length"], othername:split(line["othername:String[]"], ";") })
其中 "using periodic commit 1000" 表示每读取 1000 行数据就写入一次。
从 Person.csv 中加载人员数据并创建 Person 实体
USING PERIODIC COMMIT 1000 LOAD CSV with headers from 'https://raw.githubusercontent.com/Linusp/kg-example/master/movie/Person.csv' as line CREATE (:Person {id:line["id:ID"], name:line["name"]})
从 Country.csv 中加载国家数据并创建 Country 实体
USING PERIODIC COMMIT 1000 LOAD CSV with headers from 'https://raw.githubusercontent.com/Linusp/kg-example/master/movie/Country.csv' as line CREATE (:Country {id:line["id:ID"], name:line["name"]})
创建关系
每个关系的 csv 文件都是如下格式(以 actor.csv 为例)
":START_ID",":END_ID" "5ec851a8b7b7bbf0c9f42bbee021be00","3a20ded16ebce312f56a562e1bef7f05" "5ec851a8b7b7bbf0c9f42bbee021be00","8101549e05e6c1afbea62890117c01c6" "5ec851a8b7b7bbf0c9f42bbee021be00","111a3c7f6b769688da55828f36bbd604" "5ec851a8b7b7bbf0c9f42bbee021be00","5cc5d969f42ce5d8e3937e37d77b89b5" "5ec851a8b7b7bbf0c9f42bbee021be00","a5e6012efc56f0ca07184b9b88eb2373" "5ec851a8b7b7bbf0c9f42bbee021be00","435c8172c14c24d6cd123c529a0c2a76" "5ec851a8b7b7bbf0c9f42bbee021be00","5dfb355a385bcfe9b6056b8d322bfecb" "5ec851a8b7b7bbf0c9f42bbee021be00","5076a2f7479462dcc4637b6fe3226095" "5ec851a8b7b7bbf0c9f42bbee021be00","c7103a9ad17cf56fd572657238e49fff"
在创建关系的时候实际上是根据两个 id 查询到对应的实体,然后再为其建立关系。虽然我在准备这份数据时,已经保证了每个实体的 id 都是全局唯一的,但在没有创建索引的情况下,用这个 id 来查询实体会以遍历的形式进行,效率很差,所以在创建关系前,先创建一下索引。
为 Movie 实体的 id 属性创建索引
CREATE INDEX ON :Movie(id)
为 Person 实体的 id 属性创建索引
CREATE INDEX ON :Person(id)
为 Country 实体的 id 属性创建索引
CREATE INDEX ON :Country(id)
然后继续用 LOAD CSV 来创建关系
从 actor.csv 中加载数据并创建 actor 关系
USING PERIODIC COMMIT 1000 LOAD CSV with headers from 'https://raw.githubusercontent.com/Linusp/kg-example/master/movie/actor.csv' as line MATCH (a:Movie {id:line[":START_ID"]}) MATCH (b:Person {id:line[":END_ID"]}) CREATE (a)-[:actor]->(b)
从 composer.csv 中加载数据创建 composer 关系
USING PERIODIC COMMIT 1000 LOAD CSV with headers from 'https://raw.githubusercontent.com/Linusp/kg-example/master/movie/composer.csv' as line MATCH (a:Movie {id:line[":START_ID"]}) MATCH (b:Person {id:line[":END_ID"]}) CREATE (a)-[:composer]->(b)
从 director.csv 中加载数据创建 director 关系
USING PERIODIC COMMIT 1000 LOAD CSV with headers from 'https://raw.githubusercontent.com/Linusp/kg-example/master/movie/director.csv' as line MATCH (a:Movie {id:line[":START_ID"]}) MATCH (b:Person {id:line[":END_ID"]}) CREATE (a)-[:director]->(b)
从 district.csv 中加载数据并创建 district 关系
USING PERIODIC COMMIT 1000 LOAD CSV with headers from 'https://raw.githubusercontent.com/Linusp/kg-example/master/movie/district.csv' as line MATCH (a:Movie {id:line[":START_ID"]}) MATCH (b:Country {id:line[":END_ID"]}) CREATE (a)-[:district]->(b)
使用 Cypher 语句创建数据
严格来说,上面的 LOAD CSV 的方式,也是在用 Cypher 语句,不过说到底它还是要依赖一个外部的 CSV 文件,自由度没那么高。而 Neo4j Server 本身还提供 RESTful API,利用这个 API 就可以进行编程来完成更复杂的需求。
以创建实体为例来说明一下 Neo4j Server 的 RESTful API。假设说我们要创建三个 Person 实体,简单起见,我们假设每个 Person 实体需要有 id, name, age 三个属性,比如
[
{
"id": "person1",
"name": "张志昂",
"age": 23
},
{
"id": "person2",
"name": "刘文刀",
"age": 18
},
{
"id": "person3",
"name": "孙子小",
"age": 22
}
]
通过 RESTful API,可以一次性创建这三个 Person 实体
POST http://neo4j:neo4j_password@localhost:7474/db/data/cypher Content-Type: application/json { "query": "UNWIND {values} as data CREATE (:Person {id: data.id, name: data.name, age: data.age})", "params": { "values": [ {"id": "person1", "name": "张志昂", "age": 23}, {"id": "person2", "name": "刘文刀", "age": 18}, {"id": "person3", "name": "孙子小", "age": 22} ] } }
这种通过带参数的 query 进行批量写入的方式,和 MySQL 等数据库的接口很相似,不过在 Cypher 中可以通过 UNWIND 语句做一些复杂的事情。详见文档。
用 Python 来做的话大概是这个样子
import requests url = "http://neo4j:neo4j_password@localhost:7474/db/data/cypher" payload = { "query": ( "UNWIND {values} as data " "CREATE (:Person {id: data.id, name: data.name, age: data.age})" ), "params": { "values": [ {"id": "person1", "name": "张志昂", "age": 23}, {"id": "person2", "name": "刘文刀", "age": 18}, {"id": "person3", "name": "孙子小", "age": 22} ] } } requests.post(url, json=payload)
或者也可以使用 Neo4j 官方的 Python 客户端
import neo4j client = neo4j.GraphDatabase.driver( 'bolt://localhost:7687', auth=('neo4j', 'neo4j_password') ) with client.session() as session: query = ( "UNWIND {values} as data " "create (:Person {id: data.id, name: data.name, age: data.age})" ) values = [ {"id": "person1", "name": "张志昂", "age": 23}, {"id": "person2", "name": "刘文刀", "age": 18}, {"id": "person3", "name": "孙子小", "age": 22} ] session.run(query, {'values': values})
Cypher 查询语言
此处仅记录我个人认为常用或重要的部分,完整内容请参考官方文档。
在 Cypher 中,用小括号来表示一个实体,用中括号来表示关系,这个是 Cypher 语言中最基础的表示了。
实体的各种表示方式如下:
表示一个 Person 类型的实体,并记其名字为
a(a:Person)
表示一个 id 值为 "person1" 的实体,并记其名字为
a(a {id:"person1"})
表示任意一个实体,并记其名字为
a,之后可以通过WHERE语句来对其进行约束(a)表示一个任意的匿名实体
()
关系的各种表示方式如下
表示一个 actor 类型的实体,并记其名字为
r[r:actor]
表示任意一个实体,并记其名字为
r[r]表示一个任意的匿名实体
[]
在上面的基础之上,即可方便地表示图数据中的一条实际的边,比如说
表示命名为
m的 Movie 类型实体到命名为p的 Person 类型实体、匿名的边(m:Movie)-[]->(p:Person)
这里的 "->" 表示关系的方向是从
m到p的同上,但要求关系类型为 actor
(m:Movie)-[:actor]->(p:Person)
同上,并记关系的名字为
r(m:Movie)-[r:actor]->(p:Person)
更复杂的表示:Person
p是 Moviem1的主演,同时也是 Moviem2的导演(m1:Movie)-[r1:actor]->(p:Person)<-[r2:director]-(m2:Movie)
掌握上述表示方法后,就可以用其来进行数据的创建、查询、修改和删除操作也就是俗称的 CRUD 了。
查询实体
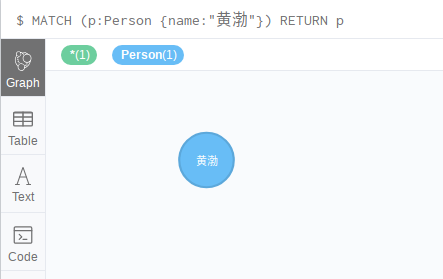
MATCH (p:Person {name:"黄渤"}) RETURN p
或者
MATCH (p:Person) WHERE p.name="黄渤" RETURN p
结果如下图所示
当然也可以不带筛选条件
MATCH (p:Person) RETURN p LIMIT 10

(没错,我非常心机地把结果排成了整齐的两排哈哈)
创建实体
语法类似这样
create (:Person {id:"ac1d6226", name:"王大锤"})
修改实体
MATCH (p:Person) WHERE p.id="ac1d6226" SET p.name="黄大锤"
删除实体
MATCH (p:Person) WHERE p.id="ac1d6226" DELETE p
注意,删除实体时,如果这个实体还有和其他实体有关联关系,那么会无法删除,需要先将其关联关系解除才可以。
查询关系
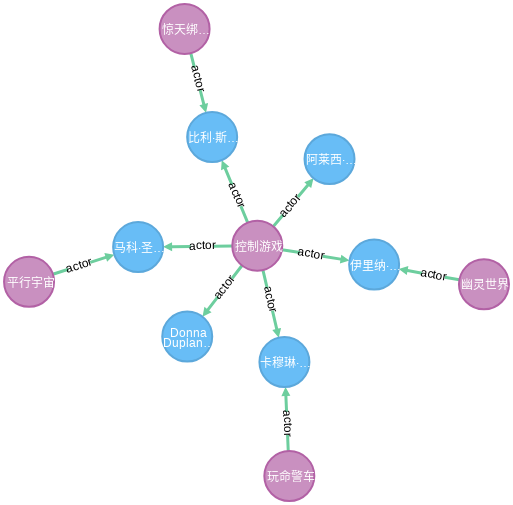
查询 actor 类型的关系,不对起点、终点做任何约束
MATCH (m)-[r:actor]->(p) RETURN * LIMIT 10
结果如下图所示:
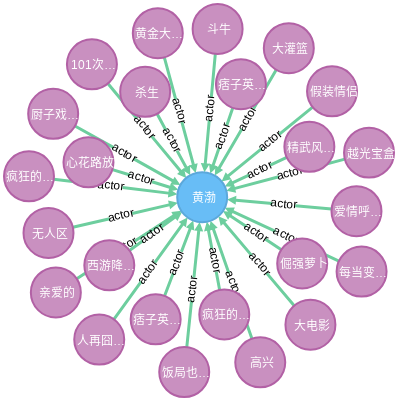
查询 actor 类型的关系,对起点(或终点)做约束,比如说,查询主演是黄渤的所有电影
MATCH (m:Movie)-[r:actor]->(p:Person) WHERE p.name="黄渤" RETURN *
结果如下图所示:
创建关系
语法如下,要求涉及到的两个实体
a和b是已经存在的。MATCH (a:Person {id:"person_id_a"}), MATCH (b:Person {id:"person_id_b"}) CREATE (a)-[:KNOWS]->(b)
之前导入的豆瓣电影图谱其实缺少人和人之间的关系,比如说宁浩和黄渤彼此都认识,可以加上这个关系
MATCH (a:Person), (b:Person) WHERE a.name="黄渤" and b.name="宁浩" CREATE (a)<-[:knows]->(b), (b)-[:knows]->(a)
删除关系
先用
MATCH语句进行查询,并为其中的关系命名,然后在 DELETE 语句中用这个关系的名字即可。MATCH (a:Person)-[r:knows]-(b:Person) WHERE a.name="黄渤" and b.name="宁浩" DELETE r
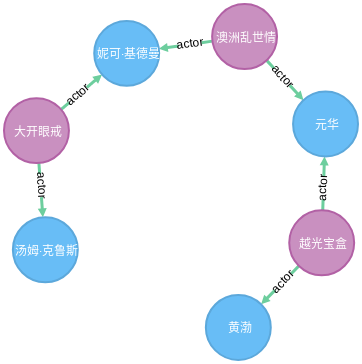
查询两个节点之间的最短路径
查询黄渤和汤姆·克鲁斯之间的最短路径
MATCH (a:Person), (b:Person), p=shortestpath((a)-[:actor*]-(b)) WHERE a.name="黄渤" and b.name="汤姆·克鲁斯" RETURN p
结果如下图所示:
CRUD 之外,索引的创建也是很重要的,如果没有创建索引或者索引设计有问题,那么可能会导致查询效率特别差。我最早开始用 Neo4j 的时候,在批量导入数据时没有建索引,导致不到五十万的数据量(包括实体和关系)的导入需要近一个小时,而在正确设置了索引之后,十几秒就完成了。对于比较慢的查询,可以用 PROFILE 语句来检查性能瓶颈。
以本文用来做示例的豆瓣电影图谱来说,如果没有给 Person.name 建立索引,那么下面这个查询语句就会很慢
MATCH (p:Person) where p.name="黄渤" RETURN p
用 PROFILE 语句做一下分析,只需要再原来的 query 前加上 PROFILE 这个关键词即可。
PROFILE MATCH (p:Person) where p.name="黄渤" RETURN p
分析结果如下图所示:
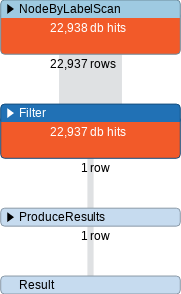
从上图来看,这个查询语句的逻辑是遍历了一下所有 Person 实体,挨个比较哪个实体的 name 是「黄渤」,这无疑是极其低效的。而在创建了索引后,PROFILE 的结果是下图这个样子:
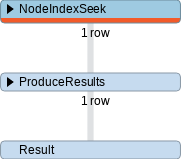
关于索引可以展开更多内容,准备另外写一篇,这里只是强调一下 PROFILE 语句的作用。