
Linux Shell技巧: 进程替代(Process Substitution)
2015-01-03What is process substitution?
"Process Substitution",我将之翻译为"进程替代",不知道有没有更相应的专业中文翻译,姑且先用着好了。它允许用将命令的输出结果当作"文件"来使用——这句话的意思是这样的,假设你有一个工具,它原本接受的参数应该是一个指代某个具体文档的"文件名",使用"进程替代"后,我们可以用其他命令的输出来作为文件的内容,让这个工具去处理。
说得比较绕,先看看 Wikipedia 上的解释:
In computing, process substitution is a form of inter-process communication that allows the input or output of a command to appear as a file. The command is substituted in-line, where a file name would normally occur, by the command shell. This allows programs that normally only accept files to directly read from or write to another program.
Process substitution on Linux
在Linux上,通过下面的形式使用 process substituion:
<(<some command> <args>)
下面用一个实际的例子来说明它的使用。
以我的工作为例,对于一个测试集,在进行完 Speaker Diarization 后,会根据标注文件(即用作参照的标准结果)计算它的错误率,而 Speaker Diarization 的错误率由三部分组成:
- Missed speech
- False alarm speech
- Speaker error
读者不必对这些词的具体含义去深究,只要知道是一个错误率的统计,同时总体错误由三个成分组成就行了。
在计算了错误率之后,会将统计结果记录在一个文件中,在这个文件中,每一行都一个音频的测试结果,形式如下:
1.wav Miss = 2.9 False = 3.4 Speaker = 1.0 Total = 7.3
现在我们有两个这样的文件,是对同一批测试集进行了两次测试后得到的结果,第一个文件 2015-05-31-der.log 的内容如下:
1.wav Miss = 2.9 False = 3.4 Speaker = 1.0 Total = 7.3 2.wav Miss = 1.0 False = 2.5 Speaker = 0.0 Total = 3.5 3.wav Miss = 2.7 False = 1.1 Speaker = 0.1 Total = 3.9
第二个文件 2015-06-22-der.log 的内容如下:
2.wav Miss = 0.5 False = 2.2 Speaker = 0.9 Total = 3.6 1.wav Miss = 2.8 False = 0.0 Speaker = 0.0 Total = 2.8 3.wav Miss = 2.4 False = 1.3 Speaker = 0.4 Total = 4.1
(注: 以上数据纯属杜撰,与我目前工作中的实际错误率情况没有任何关系)
我需要根据这两个文件,得到每个音频在两次测试中各个成分的对比情况,希望输出的每一行是这样的:
1.wav Miss = 2.9 False = 3.4 Speaker = 1.0 Total = 7.3 | Miss = 2.8 False = 0.0 Speaker = 0.0 Total = 2.8
比较容易想到需要根据文件名进行 sort ,然后使用 paste 把两个文件拼接起来,那么很自然地可以这样写:
sort -k1,1 2015-05-31-der.log > 2015-05-31-der-sorted.log sort -k1,1 2015-06-22-der.log | cut -d ' ' -f 2- > 2015-06-22-der-sorted.log paste -d '|' 2015-05-31-der-sorted.log 2015-06-22-der-sorted.log rm *-sorted.log
使用进程替代的话,我可以用一行就搞定,而且不需要生成临时文件:
paste -d '|' <(sort -k1,1 2015-05-31-der.log) <(sort -k1,1 2015-06-22-der.log | cut -d ' ' -f 2-)
另外一个例子,就是使用 diff 比较两个文件内容的时候,而且我们关心的是某个文件中某个记录在另外一个文件中有没有,不希望受次序影响时——diff是按行来进行文件内容对比的。还是来假设一个场景吧。
假设我和我的一个朋友各自出去购物,完了回来想比较一下我们购买东西的区别:我买的东西里面哪些他没有买,他买的哪些我没有买。
我的购物清单是 shopping-list-1.txt ,内容如下:
苹果 上衣 毛巾 耳机 无线键盘
我朋友的购物清单是 shopping-list-2.txt ,内容如下:
耳机 苹果 无线键盘 科幻小说 五号电池 体重秤 移动电源
那么相比不用进程替代的传统办法,使用进程替代的办法会简单很多,一行搞定:
diff <(sort shopping-list-1.txt) <(sort shopping-list-2.txt)
结果如下:
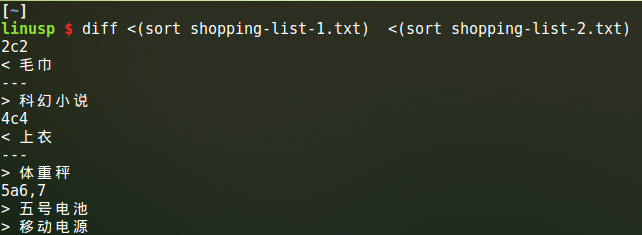
可以看到,我买了而我朋友没买的东西是:
毛巾 上衣
我朋友买了而我没买的东西是:
科幻小说 体重秤 五号电池 移动电源
Some more
实际上,进程替代也不是什么很新奇的东西,Wikipedia 上说,它是进程间通信的一种方式,事实上也确实是这样。在 Linux 上使用进程替代的时候,系统会创建一个临时的文件描述符,然后将用以替代的进程的输出和这个文件描述符关联起来,这个可以通过以下命令来验证:
echo <(sort shopping-list-1.txt)
不出意外,应该会看到这样的输出:
/dev/fd/63
"fd"就是文件描述父(File Description)的缩写,但你去/dev/fd/下面找这个文件描述符,却会发现找不到,那是因为这个文件描述符是临时的,在传给"echo"命令后就被释放了。
此外,进程替代并不能和文件完全等价,这一点要切记。进程替代所建立的"对象",是不能进行写入和随机读取操作的。不能写入的话应该很好理解,因为如果进行写操作,将会写到那个临时的文件描述符里面去,而这个临时文件描述符会被迅速地释放掉,而且由于创建的这个"文件"——姑且这么称呼,不是一个 regular file (与之相对的是 special file),如果在写入时有严格的检查,甚至连写入都会被拒绝;有时候我们需要对文件进行随机读取,比如 C 语言里的 fseek() 函数的操作,这样的操作将不能在进程替代产生的临时对象上正常运作。
总的来说,我个人是很喜欢这个功能的,减少了处理数据时不少的工作量。
That's it!