
文本相似度量方法(2): LCS 和编辑距离
2016-03-31本文是《文本相似度量方法(1): 概览》 一文的后续,着重讲述最长公共子序列(Longest Common Subsequence, LCS)和编辑距离的原理和实现。
最长公共子序列
问题定义
对给定序列 A 和 B, 满足以下条件的一个序列 C 被称为 A 和 B 的公共子序列:
- C 中每一个元素都对应 A 和 B 中一个元素
- 从 C 中挑选两个元素 \(C_{i}\) 和 \(C_{j}\) ,其中 \(i\) 和 \(j\) 表示这两个元素在 C 中的序号(从左至右),假设这两个元素分别对应 \(A_{m}\) 和 \(A_{n}\) ,那么有 \((j - i)\cdot(n - m)\gt 0\),在 B 中对应的两个元素同理
比如说给定 \(A =\) "打南边来了个喇嘛,手里提拉着五斤鳎目", \(B =\) "打北边来了个哑巴,腰里别着个喇叭" ,以下都是 A 和 B 的子序列:
- "打边"
- "打边来了个"
- "边个着"
在所有可能的 C 中,长度最大的即所谓 "最长公共子序列"。上述例子中 A 和 B 的最长公共子序列是: "打边来了个,里着"。如下图所示:

直观感受上,我们可以认为,如果 A 和 B 的最长公共子序列越长,A 和 B 就越相似。这也是用最长公共子序列来度量文本相似程度的思想。
求解方法
LCS 是一个比较经典的算法问题,了解动态规划的读者应该对它不会陌生。
要求解 LCS,朴素的想法是将 A 的所有子序列都枚举一遍,看是否是 B 的子序列,然后从中挑选出最长的。对给定字符串 A ,假定其长度为 \(L\),其所有可能的子序列数量为 \(\sum_{i=1}^{L}\binom{L}{i}\) 也就是 \(2^{L} - 1\) ,所以暴力求解方法的复杂度至少是指数级的,这显然是不可取的。
通常我们用动态规划方法来求解 LCS 问题。
不难发现 LCS 的求解可以按照以下方法来得到:
- 对比 A 和 B 的第一个字符,如果相等,则转入步骤 2,否则转入步骤 3
- 将 A 和 B 的第一个字符记录为 LCS 的第一个字符,求 A 和 B 剩下部分的 LCS (转回步骤 1,下同)
- 将 A 去掉第一个字符,用剩下的部分和 B 一起计算 LCS,转入步骤 4
- 将 B 去掉第一个字符,用剩下的部分和 A 一起计算 LCS,转入步骤 5
- 比较第 3 步和第 4 步得到的 LCS,其中较长的就是 A 和 B 的 LCS.
上述过程很明显是一个递归过程,所以可以简单地实现出来。
# coding: utf-8 def lcs(a, b): if not a or not b: return [] res = [] if a[0] == b[0]: res.append(a[0]) res.extend(lcs(a[1:], b[1:])) else: lcs_one = lcs(a[1:], b) lcs_two = lcs(a, b[1:]) res = lcs_one if len(lcs_one) > len(lcs_two) else lcs_two return res res = lcs('hello world', 'hero word') print ''.join(res)
上述代码可以解决问题,看起来行数也不多,但其实还是有问题的,那就是递归树的存在导致了大量的重复计算、以及可能存在的栈溢出风险。举个栗子,计算 "hello" 和 "hero" 的过程如下图所示:
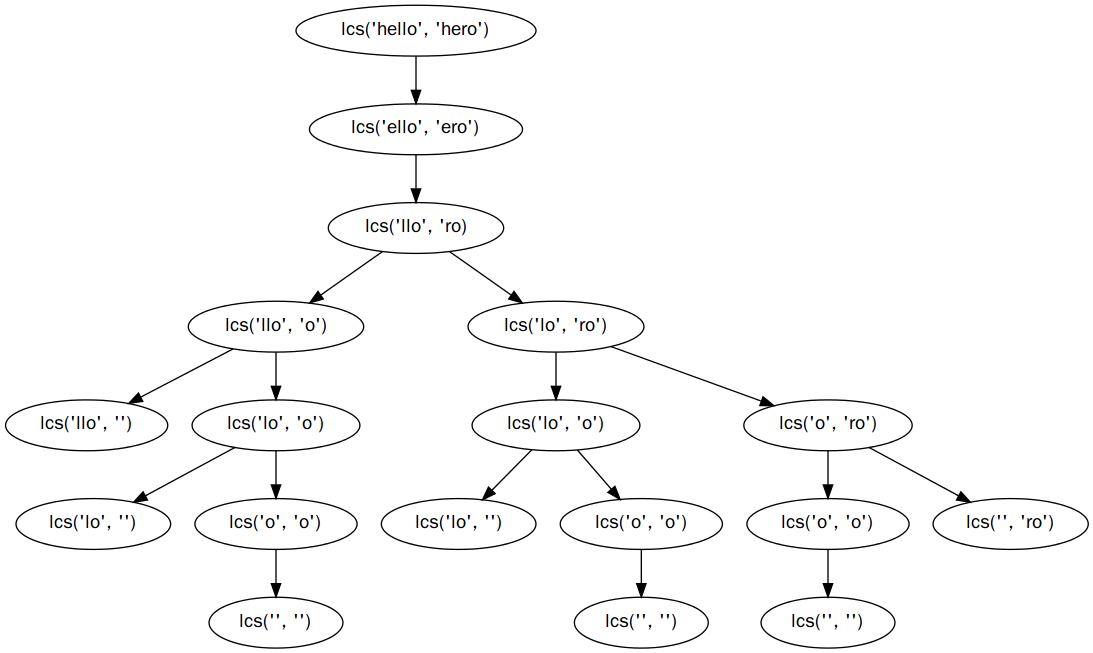
可以看到 "lcs('lo', 'o')" 被计算了两次。
解决上面提到的问题的方法是将递归方法改为循环方法。用 \(m\) 表示 A 的长度,用 \(n\) 表示 B 的长度,我们可以构建一个 \(m\times n\) 的矩阵 \(D\) ,用来保存上面递归过程中计算到的 A 和 B 的公共子序列。
具体方法是, \(D_{i,j}\) 表示去除 A 的前 i 个元素后的子串 \(A^{\prime}\) 和 B 去掉前 j 个元素后的子串 \(B^{\prime}\) 的 LCS。这样我们首先计算 \(D_{m,n}\) ,然后计算 \(D_{m-1,n}\) 和 \(D_{m,n-1}\) ,再计算 \(D_{m-1,n-1}\),依次类推。为什么可以这么做呢?仔细看看之前提到的递归过程中的 2、3、4 步,以及上面那张计算 "hello" 和 "hero" 的 LCS 的递归树图,可以发现计算最后都可以归结为计算 A 和 B 尾部片段的 LCS 。
我们发现上面的形式话表述不太直观,如果能先计算 \(D_{0,0}\) 是不是更好一些呢?是的,只要把之前提到的递归规则中的 "比较 A 和 B 的第一个字符" 改为 "比较 A 和 B 的最后一个字符" 并对步骤 2、3、4 做出相应的改变即可。
这样,LCS 的算法可以改写为:
# coding: utf-8 import numpy as np def lcs(a, b): m, n = len(a), len(b) # 为便于计算,为 D 多增加一行一列 # 其中第一行和第一列中的元素保持为空字符串 D = np.zeros((m+1, n+1), dtype=object) D[:] = '' # 初始化为空字符串 for idx_a, ch_a in enumerate(a, 1): for idx_b, ch_b in enumerate(b, 1): # 若 D 不增加一行一列,下标 idx_a-1/idx_b-1 要判断是否非负 if ch_a == ch_b: D[idx_a, idx_b] = D[idx_a-1, idx_b-1] + ch_a else: lcs_one = D[idx_a, idx_b-1] lcs_two = D[idx_a-1, idx_b] if len(lcs_one) > len(lcs_two): D[idx_a, idx_b] = lcs_one else: D[idx_a, idx_b] = lcs_two return D[m, n] print lcs('hello', 'hero')
当然实际上我们不会去用一个二维数组来保存计算过程中用到的(非最长)公共子序列,这样虽然很直观,但是在内存使用上有点丑陋。标准的做法是只记录这些公共子序列的长度,计算完整个长度矩阵后,再从最后的位置回溯取得 LCS 。
先观察一下计算 "lcs('hello', 'hero')" 时得到的公共子序列矩阵:
| h | e | r | o | ||
|---|---|---|---|---|---|
| - | - | - | - | - | |
| h | - | h | h | h | h |
| e | - | h | he | he | he |
| l | - | h | he | he | he |
| l | - | h | he | he | he |
| o | - | h | he | he | heo |
矩阵中出现过的公共子序列有: 'h', 'he' 和 'heo'。从中我们 似乎可以发现这么一个规律: 从上往下逐行查看,这三个公共子序列 第一次 出现的时候,恰好就是 'hello' 和 'hero' 中有字符相等的时候,换成记录长度后,也就对应某个特定的长度值第一次出现的时候。
| h | e | r | o | ||
|---|---|---|---|---|---|
| - | - | - | - | - | |
| h | - | 1 | 1 | 1 | 1 |
| e | - | 1 | 2 | 2 | 2 |
| l | - | 1 | 2 | 2 | 2 |
| l | - | 1 | 2 | 2 | 2 |
| o | - | 1 | 2 | 2 | 2 |
就这个例子而言,我们 似乎 可以这样来根据长度矩阵得到 LCS (行/列序号从 0 开始,后同):
- 在第 1 行第 1 列找到 1 ,对应的字符是 'h'
- 在第 2 行第 2 列找到 2 ,对应的字符是 'e'
- 在第 5 行第 4 列找到 3 ,对应的字符是 'o'
这种方法 直观上感觉是对的,但实际上是有问题的 ,下面是计算 'GCGGACTG' 和 'GCCCTAGCG' 时得到的长度矩阵。
| G | C | C | C | T | A | G | C | G | ||
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| G | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| C | 0 | 1 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| G | 0 | 1 | 2 | 2 | 2 | 2 | 2 | 3 | 3 | 3 |
| G | 0 | 1 | 2 | 2 | 2 | 2 | 2 | 3 | 3 | 4 |
| A | 0 | 1 | 2 | 2 | 2 | 2 | 3 | 3 | 3 | 4 |
| C | 0 | 1 | 2 | 2 | 3 | 3 | 3 | 3 | 4 | 4 |
| T | 0 | 1 | 2 | 2 | 3 | 4 | 4 | 4 | 4 | 4 |
| G | 0 | 1 | 2 | 2 | 3 | 4 | 4 | 5 | 5 | 5 |
如果按照刚才的做法来反推 LCS ,会得到下面的结果:
- 在第 1 行第 1 列找到 1 ,对应的字符是 'G'
- 在第 2 行第 2 列找到 2 ,对应的字符是 'C'
- 在第 3 行第 7 列找到 3 ,对应的字符是 'G'
- 在第 4 行第 9 列找到 4 ,对应的字符是 'G'
- 第 4 步找到的 'G' 是 'GCCCTAGCG' 的最后一个字符(表中最后一列),因此停止
实际上真正求得的 LCS 长度应该是 5 ,为 'GCGCG'、'GCACG' 或 'GCCTG',而不是 'GCGG'。问题出在哪呢? LCS 可以看成是一个最优解,但到达最优解的路径可能有不止一条,而且局部的最优解并不一定是最优解的组成部分,所以前面提到的贪心方法在有些情况下可以得到正确的结果,但有的情况下就会出错。
正确的做法是从长度矩阵右下角,根据长度矩阵的计算规则往前反推,这样就能保证得到的结果是最长的公共子序列。
先把子序列长度矩阵的计算方法实现:
import numpy as np def lcs_matrix(a, b): m, n = len(a), len(b) matrix = np.zeros((m+1, n+1), dtype=int) for idx_a, ch_a in enumerate(a, 1): for idx_b, ch_b in enumerate(b, 1): if ch_a == ch_b: matrix[idx_a, idx_b] = matrix[idx_a-1, idx_b-1] + 1 else: matrix[idx_a, idx_b] = max( matrix[idx_a, idx_b-1], matrix[idx_a-1, idx_b] ) return matrix print lcs_matrix('GCGGACTG', 'GCCCTAGCG')
根据长度矩阵的计算规则,可以按照以下步骤来反推出 LCS:
- 首先定位到长度矩阵右下角位置
- 如果当前位置的值为 0 ,则停止;否则转到步骤 3
- 如果当前位置对应的 A 和 B 的元素相等,则向当前位置的左上角后退一步(行号和列号各减 1),并回到步骤 2,否则转到步骤 4
- 检查矩阵当前位置左边的值和上边的值,跳转到其中值更大的那个位置(如果相等,则在往上和往左中选择一个方向),回到步骤 2
用代码实现出来大概是这样:
import numpy as np def lcs_backtrace(a, b, matrix): idx_a, idx_b = len(a) - 1, len(b) - 1 lcs_list = [] while matrix[idx_a+1, idx_b+1] > 0: if a[idx_a] == b[idx_b]: lcs_list.append(a[idx_a]) idx_a -= 1 idx_b -= 1 else: upper_value = matrix[idx_a, idx_b+1] left_value = matrix[idx_a+1, idx_b] if upper_value > left_value: idx_a -= 1 else: idx_b -= 1 lcs_list.reverse() return lcs_list a = 'GCGGACTG' b = 'GCCCTAGCG' matrix = np.array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 1, 1, 1, 1, 1, 1, 1, 1, 1], [0, 1, 2, 2, 2, 2, 2, 2, 2, 2], [0, 1, 2, 2, 2, 2, 2, 3, 3, 3], [0, 1, 2, 2, 2, 2, 2, 3, 3, 4], [0, 1, 2, 2, 2, 2, 3, 3, 3, 4], [0, 1, 2, 3, 3, 3, 3, 3, 4, 4], [0, 1, 2, 3, 3, 4, 4, 4, 4, 4], [0, 1, 2, 3, 3, 4, 4, 5, 5, 5]], dtype=int) print lcs_backtrace(a, b, matrix)
需要注意的是,LCS 结果可能并不唯一。
数学表示与相似度量
上述求解方法可以用数学语言表示如下:
\[\begin{eqnarray}LCS(A_{i}, B_{j}) = \begin{cases} 0 & if\quad i=0\quad or\quad j=0\\ LCS(A_{i-1}, B_{j-1})+a_{i} & if\quad a_{i}=b_{j}\\ longest(LCS(A_{i}, B_{j-1}), LCS(A_{i-1}, B_{j})) & if\quad a_{i}\neq b_{j} \end{cases}\end{eqnarray}\]
其中 \(A_{i}\) 表示 A 的前 \(i\) 个字符组成的字符串,\(B_{j}\) 同理。
直观上,我们可以认为 A 和 B 的 LCS 越长,那么 A 和 B 就越相似。为了使所有用于比较的 (A, B) 对得到的相似度量能进行横向比较,定义 LCS 相似度为:
\[S(A, B) = \frac{2\cdot |LCS(A, B)|}{|A| + |B|}\]
这样得到的相似度的值就被变换到 [0, 1] 区间中了。
编辑距离
所谓编辑距离
编辑距离最早由俄罗斯科学家 Levenshtein 提出,故又称 "Levenshtein 距离"。其定义为: 给定两个字符串 A 和 B,将 A 通过删除、插入、替换操作转换为 B 所需要的最少操作次数。
比如将 "kitten" 转换为 "sitting" 需要进行如下操作:
- 替换操作: kitten -> sitten (k -> s)
- 替换操作: sitten -> sittin (e -> i)
- 插入操作: sittin -> sitting (SPC -> g)
我们就说 "kitten" 相对 "sitting" 的编辑距离是 3。
编辑距离衡量的是两个字符串之间的差异程度,所以差异程度越小,相似程度就越大了。
求解方法
编辑距离的核心过程 LCS 在我看来是一样的,可以看一下它的数学描述:
\[\begin{eqnarray}LEV(A_{i}, B_{j}) = \begin{cases} max(i, j) & if\quad min(i, j)=0\\ min(LEV(A_{i-1}, B_{j})+1, LEV(A_{i}, B_{j-1})+1, LEV(A_{i-1}, B_{j-1})) & if\quad a_{i}=b_{j}\\ min(LEV(A_{i-1}, B_{j})+1, LEV(A_{i}, B_{j-1})+1, LEV(A_{i-1}, B_{j-1})+1) & if\quad a_{i}\neq b_{j}\\ \end{cases}\end{eqnarray}\]
按照其数学描述,可以实现如下:
# coding: utf-8 import numpy as np def edit_distance(a, b): m, n = len(a), len(b) dis_matrix = np.zeros((m+1, n+1), dtype=int) # 初始化距离矩阵的第 0 行和第 0 列 dis_matrix[0, :] = np.arange(n+1) dis_matrix[:, 0] = np.arange(m+1) # 开始计算 for idx_a, ch_a in enumerate(a, 1): for idx_b, ch_b in enumerate(b, 1): cur_dis = None dis_left = dis_matrix[idx_a, idx_b-1] dis_upper = dis_matrix[idx_a-1, idx_b] dis_upper_left = dis_matrix[idx_a-1, idx_b-1] if ch_a == ch_b: cur_dis = min(dis_left+1, dis_upper+1, dis_upper_left) else: cur_dis = min(dis_left+1, dis_upper+1, dis_upper_left + 1) dis_matrix[idx_a, idx_b] = cur_dis return dis_matrix[m, n] print edit_distance('kitten', 'sitting')
从编辑距离到相似度量
与 LCS 不同的是,编辑距离衡量的是差异性,所以用编辑距离来表示相似程度,按照如下式子进行转换:
\[S(A, B)=1-\frac{LEV(A, B)}{max(|A|, |B|)}\]
一点看法
LCS 和编辑距离都是基于相似的动态规划方法来进行求解,它们之间是有很强的共性的。不过 LCS 强调的是 "公共子序列" 这个概念,而编辑距离强调删除、插入、替换这三种编辑操作。实际上还有扩充的编辑距离,比较经典的是 Damerau-Levenshtein 距离,它在 Levenshtein 距离定义的三种编辑操作之外还加入了 "交换相邻字符" 这个操作,因为在输入时将邻近字符的顺序搞错的事情实在是蛮常见的(代码里的 typo 多是这种类型 XD)。
编辑距离和 LCS 不同的另一点,那就是在 LCS 中,用于比较的两个串的 地位 是等价的,而在编辑距离及其衍生方法中,一般会有一者被认为是 标准的 。
另外,在生物信息学中,序列比对是非常常见的计算,比如 DNA序列和氨基酸序列的比对。在这个领域中,经常使用 Needleman-Wunsch 算法和 Smith-Waterman 算法来进行相关的处理。大致上,这两种算法和编辑距离也很相似,都是基于动态规划的算法,但在生物信息学中, 序列的缺失 往往是更不能容忍的现象,因此对应于编辑距离中的删除错误,在这两种算法中,会给予比插入错误和替换错误更高的惩罚值。这些都是后话了,计划在下一篇博客中再详细讨论。
在应用上,LCS 主要被应用于版本控制和 diff 工具中,下面是摘自 Git 源代码中的一个片段
for (i = 1, baseend = base; i < origbaselen + 1; i++) { for (j = 1, newend = new; j < lennew + 1; j++) { if (match_string_spaces(baseend->line, baseend->len, newend->line, newend->len, flags)) { lcs[i][j] = lcs[i - 1][j - 1] + 1; directions[i][j] = MATCH; } else if (lcs[i][j - 1] >= lcs[i - 1][j]) { lcs[i][j] = lcs[i][j - 1]; directions[i][j] = NEW; } else { lcs[i][j] = lcs[i - 1][j]; directions[i][j] = BASE; } if (newend->next) newend = newend->next; } if (baseend->next) baseend = baseend->next; }
而编辑距离则常见于模糊匹配、拼写检查等场景中,比如 GNU Aspell 使用的就是 Levenshtein 距离,而 GNU Ispell 则使用 Damerau-Levenshtein 距离。从我曾经的工作经历来看,在语音识别中和 OCR (光学字符识别)中,编辑距离也用于衡量识别结果的质量。此外在图像处理领域,也有使用编辑距离的场景。
虽然说基于 LCS 或者编辑距离的文本相似方法都是朴素的、从表面上进行的判断,没有办法深入到语义层面,但用来做一些简单场景的分析已经是足够了,有必要的话还可以对其进行扩充,比如以词为单位来进行处理,比如扩充 item 和 item 的比较方法而不是简单地对比文本组成是否一致。
(待续)