
使用 Keras 实现简单的 Sequence to Sequence 模型
2016-05-29Sequence to Sequence Model
Sequence to Sequence 模型是近几年来比较热门的一个基于 RNN 的模型,现在被广泛运用于机器翻译、自动问答系统等领域,并且取得了不错的效果。该模型最早在 2014 年被 Cho 和 Sutskever 先后提出,前者将该模型命名为 "Encoder-Decoder Model",后者将其命名为 "Sequence to Sequence Model",两者有一些细节上的差异,但总体思想大致相同,所以后文不做区分,并简称为 "seq2seq 模型"。
seq2seq 模型利用了 RNN 对时序序列天然的处理能力,试图建立一个能 直接处理变长输入与变长输出 的模型——机器翻译是一个非常好的例子。传统的机器翻译系统当然也能根据变长的输入得到变长的输出,但这种处理能力是通过很多零碎的设置、规则和技巧来达成的,而 seq2seq 模型不一样,它结构简单而自然,对变长输入和变长输出的支持也是简单直接的。来看一下它的结构:
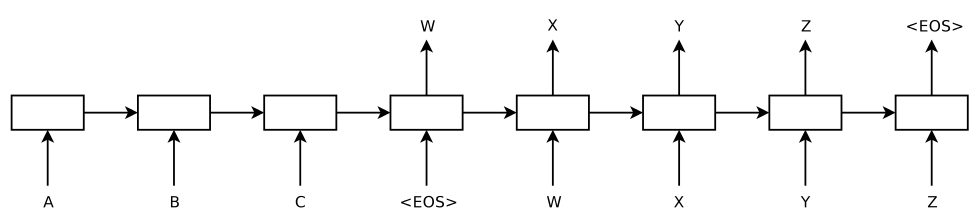
上图是一个已经在时间维度上展开(unroll)的 seq2seq 模型,其输入序列是 "ABC" ,其输出序列是 "WXYZ" 。模型由两个 RNN 组成:第一个 RNN 接受输入,并将其表示成一个语义向量,在上面这个例子中,A、B、C 和表示序列结束的特殊符号 <EOS> 依次输入,并在读取到 <EOS> 时终止接收输入,并输出一个向量作为 "ABC" 这个输入向量的语义表示,因此也被称作 "Encoder";第二个 RNN 接受第一个 RNN 产生的输入序列的语义向量,然后从中产生出输出序列,因此也被称作 "Decoder"。
更多的细节见我的两篇论文阅读笔记:
Keras 简介
Keras 是一个 Python 的深度学习框架,它提供一些深度学习方法的高层抽象,后端则被设计成可切换式的(目前支持 Theano 和 TensorFlow)。4 月份 Keras 发布了 1.0 版本,意味着 Keras 的基础特性已经基本稳定下来,不用担心其中的方法会发生剧烈的变化了。
(注: 因为发布 1.0 版本时间还比较短,网上的一些例子有不少还使用的旧版本的方法,建议多多查阅文档)
在 Keras 中实现神经网络模型的方法很简单,首先实例化一个 "Sequential" 类型的模型,然后往其中添加不同类型的 layer 就可以了。比如要实现一个三层的 MLP,可以这样:
from keras.models import Sequential from keras.layers import Dense model = Sequential() model.add(Dense(input_dim=4, output_dim=9, activation="relu")) model.add(Dense(output_dim=3, activation="softmax"))
其中的 "Dense" 是经典的全连接层(在 Caffe 中被称为 InnerProduct)。每个网络层的输入、输出参数和激活函数都可以方便地直接设置。
另外,由于目前使用的后端 Theano 和 TensorFlow 都是基于符号计算的,上述模型定义后只是产生了一个符号计算的图,并不能直接用来训练和识别,所以需要进行一次转换,调用 "Sequential" 的 compile 方法即可:
model.compile(loss="categorical_crossentropy", optimizer="sgd")
compile 时需要设定训练时的目标函数和优化方法,而 Keras 中已经实现了目前常用的目标函数和优化方法,详情见:
训练时则要求数据是 Numpy 的多维数组形式,保证这一点的情况下使用 "Sequential" 的 "fit" 方法即可,如:
model.fit(IRIS_X, IRIS_Y, nb_epoch=300)
如果需要进行交叉验证,不用自己手工去分割训练数据,只需要使用 "fit" 方法的 "validation_split" 参数即可,其值应为 0-1 的浮点数,表示将训练数据用于交叉验证的比例,如:
model.fit(IRIS_X, IRIS_Y, nb_epoch=300, validation_split=0.1)
训练过程中会将 loss 打印出来,方便了解模型训练情况:
Epoch 1/100 1024000/1024000 [==============================] - 725s - loss: 0.7274 - val_loss: 0.6810 Epoch 2/100 1024000/1024000 [==============================] - 725s - loss: 0.6770 - val_loss: 0.6711 Epoch 3/100 1024000/1024000 [==============================] - 723s - loss: 0.6723 - val_loss: 0.6680
在 Keras 中也提供模型的持久化方法,通过 "Sequential.to_json" 方法可以将模型结构保存为 json 然后写入到文件中,通过 "Sequential.save_weights" 方法可以直接将模型参数写入文件,结合这两者就可以将一个模型完整地保存下来:
def save_model_to_file(model, struct_file, weights_file): # save model structure model_struct = model.to_json() open(struct_file, 'w').write(model_struct) # save model weights model.save_weights(weights_file, overwrite=True)
对于保存下来的模型,当然也有对应的方法来进行读取:
from keras.models import model_from_json def load_model(struct_file, weights_file): model = model_from_json(open(struct_file, 'r').read()) model.compile(loss="categorical_crossentropy", optimizer='sgd') model.load_weights(weights_file) return model
Pig Latin: Sequence to Sequence 实践
Pig Latin 的一种翻译叫做 “儿童黑话”,罗嗦一点的意译是 “故意颠倒英语字母顺序拼凑而成的黑话”,它有很多种变种规则,这里只取其原始的、最简单的两条规则:
如果单词起始的字母是 元音 ,那么在单词后面添加一个 'yay'
'other' -> 'otheryay'
如果单词起始的字母是 辅音 ,那么将起始到第一个元音之前所有的辅音字母从单词首部挪到尾部,然后添加一个 'ay'
'book' -> 'ookbay'
Pig Latin 是一个典型的输入和输出都是变长序列的问题,我们通过它来了解一下基于 Keras 的简单 seq2seq 模型。
首先我们需要准备训练数据,在这个问题中,由于规则是确定的,我们可以来生成大量的数据,如下所示,简单几行代码就可以啦:
from itertools import dropwhile def is_vowel(char): return char in ('a', 'e', 'i', 'o', 'u') def is_consonant(char): return not is_vowel(char) def pig_latin(word): if is_vowel(word[0]): return word + 'yay' else: remain = ''.join(dropwhile(is_consonant, word)) removed = word[:len(word)-len(remain)] return remain + removed + 'ay'
然后需要实现一个简单的 seq2seq 模型
from keras.models import Sequential from keras.layers.recurrent import LSTM from keras.layers.wrappers import TimeDistributed from keras.layers.core import Dense, RepeatVector def build_model(input_size, max_out_seq_len, hidden_size): model = Sequential() model.add(LSTM(input_dim=input_size, output_dim=hidden_size, return_sequences=False)) model.add(Dense(hidden_size, activation="relu")) model.add(RepeatVector(max_out_seq_len)) model.add(LSTM(hidden_size, return_sequences=True)) model.add(TimeDistributed(Dense(output_dim=input_size, activation="linear"))) model.compile(loss="mse", optimizer='adam') return model
对上述代码作一点解释:
- Encoder(即第一个 LSTM) 只在序列结束时输出一个语义向量,所以其 "return_sequences" 参数设置为 "False"
- Decoder(即第二个 LSTM) 需要在每一个 time step 都输出,所以其 "return_sequences" 参数设置为 "True"
- 使用 "RepeatVector" 将 Encoder 的输出(最后一个 time step)复制 N 份作为 Decoder 的 N 次输入
- TimeDistributed 是为了保证 Dense 和 Decoder 之间的一致,可以不用太关心
之所以说是 "简单的 seq2seq 模型",就在于第 3 点其实并不符合两篇论文的模型要求,不过要将 Decoder 的每一个时刻的输出作为下一个时刻的输入,会麻烦很多,所以这里对其进行简化,但用来处理 Pig Latin 这样的简单问题,这种简化问题是不大的。
另外,虽然 seq2seq 模型在理论上是能学习 "变长输入序列-变长输出序列" 的映射关系,但在实际训练中,Keras 的模型要求数据以 Numpy 的多维数组形式传入,这就要求训练数据中每一条数据的大小都必须是一样的。针对这个问题,现在的常规做法是设定一个最大长度,对于长度不足的输入以及输出序列,用特殊的符号进行填充,使所有输入序列的长度保持一致(所有输出序列长度也一致)。
在 Pig Latin 这个问题上,用收集的 2043 个长度在 3-6 的常用英文单词作为原始数据,去除其中包含非 a-z 的字母的单词,最后得到了 2013 个有效单词。然后根据的规则将这些单词改写为 Pig Latin 形式的单词,作为对应的输出。然后在单词前都添加开始符 BEGIN_SYMBOL、在单词后都添加结束符 END_SYMBOL,并用 END_SYMBOL 填充 使其长度为 15 ,并将每一个字符用 one-hot 形式进行向量化(向量化时用于填充的空白符用全 0 向量表示),最后得到大小都为 2013x10x28 的输入和输出。
训练的话,batch_size 设置为 128, 在 100 个 epoch 后模型收敛到了一个令人满意的程度。
在一些训练集之外的数据上,能看到网络给出了正确的结果:
ok -> okyay sin -> insay cos -> oscay master -> astermay hanting -> antinghay
当然,也有一些反例:
dddodd -> oddddray mxnet -> inetlay zzzm -> omhmay
但是无论结果错误程度如何,能看到结果总是以 'ay' 结尾的!
完整代码见: soph/demos/pig_latin.py