
个人知识管理系统(二): 信息的取舍与收集
2016-10-22目录
接上一篇 《个人知识管理系统(一): 概述》 ,本篇主要谈一下我是如何对信息进行取舍和收集的。
信息的取舍
前文已经提过,信息的取舍是建立整个系统的第一步。而信息取舍也是分阶段的: 最初的阶段,剔除对个人来说无用的信息;第二个阶段,区分有用信息的重要程度,只保留重要的信息。
第一个阶段是对信息的初步过滤,这个阶段可以发生在很多地方,不一定说是要整合在 PKM 之中。比如说屏蔽实际上不熟悉的微信好友的朋友圈,这是在系统之外;比如说在 RSS 阅读器中设置过滤规则将一些不感兴趣的信息自动标记为已读,这是在系统内。这个步骤是比较容易做到的。
第二个阶段是按照信息的重要程度来进行取舍,相比第一个阶段要难得多,很多信息看起来都是有用的而让我们难以舍弃。但事实上低优先级的信息可能会在接收到的信息中占据很大的比利,如果不进行取舍,那么将大量时间花费在低质量信息的处理上,那只会事倍功半。
需要说一下的是,系统外的信息取舍同样重要,因为如果被系统外的信息耗费了太多精力,在系统中的注意力就会减少,刷微博、刷知乎就是很典型的事例。
对于信息的重要程度的区分,我按采铜的「收益值-半衰期」四象限法来进行区分。以下是采铜在知乎问题「你有什么相见恨晚的知识推荐给年轻人?」的回答中对这个概念的描述:
当我们评价一个事情值不值得去做、应该花多少精力去做的时候,应该抛弃单一的视角,而是分从两个不同的维度来看,一是该事件将给我带来的收益大小(认知、情感、物质、身体方面的收益皆可计入),即「收益值」;二是该收益随时间衰减的速度,我称为「收益半衰期」,半衰期长的事件,对我们的影响会持续地较久较长。
以半衰期长为优先条件,不同的信息按照重要程度衰减的顺序,可以这样划分:
高收益值长半衰期的信息
如:
- 深度学习和自然语言处理方面的论文
- 像「阡陌的自留地」、「战隼的学习探索」这样的方法论博客
- 深度学习和自然语言处理方面的深度文章
低收益值长半衰期的信息
如:
- 神话学、哲学、历史等方面的专著
- 数学、计算机科学等学科的系统性知识
高收益短半衰期的信息
如:
- 段子、笑话之类的「趣味性」信息
- 休闲小说
低收益短半衰期的信息
如:
- 微信、微博及其他社区或社交平台上的信息
- 社会/行业的热点资讯
长半衰期的信息,基本上都需要深度的阅读,因此需要养成在固定的时间段内进行处理的习惯,这样从心理上和环境上都能保持比较稳定的状态,有利于快速进入阅读状态;短半衰期的信息,多半具有时效性,且数量庞大,因此需要进行筛选以减少数量,同时利用各种碎片化时间快速处理。
结合前面的「两个阶段」,我的总体的取舍方法是这样的:
- 减少社交平台上的信息量: 微信上屏蔽「不熟悉好友」的朋友圈,微博和知乎上限制关注数量
- 减少资讯类信息的数量,只对每日的热点做大概了解,比如使用「即刻」而不是订阅一堆资讯类信息源
- 降低信息冗余,删除不同渠道的相同信息源(比如同一个人的知乎专栏和微信公众号),删除只做信息转发的信息源
- 按照自己的兴趣和规划,对信息源进行分类,删除无法分类的信息源
- 维护一个关键词列表,在信息汇总的地方进行二次过滤
此外,尽量避免使用「稍后阅读」类工具,也不要在浏览器书签或者笔记工具中上收藏一大堆文章 —— 对此有些人可能会有异议,但就我而言,信息的收集只是为后续的知识提炼准备材料,我的目的 不是建立一个可供快速搜索的庞大资料库 。所有收集到的信息,都应该在一定时间内被消化然后清除掉,如果有哪些信息一直滞留在收集阶段,那么这样的信息对我来说是无用甚至有害的。
信息的收集
RSS 和「即刻」
我主要使用 RSS 阅读器来收集、汇总不同的信息源。
首先介绍一下 RSS,它是「简单信息聚合(Really Simple Syndication)」的简称,是一种标准化的信息格式,允许人们将不同的信息来源以统一的格式进行聚合和处理。RSS 最初用来整合不同新闻站点的内容,后来在博客上被广泛使用。需要明确的是,RSS 只是一种「信息标准」,包括以特定结构和格式来存储信息,以及对信息的更新,而 RSS 阅读器则是支持这种信息标准的一个整合工具,用来接收不同信息源的 RSS 输出,然后在统一的界面中进行呈现。
RSS 阅读器的好处是保证阅读环境和交互的统一,以及基于统一信息标准上的丰富的扩展操作。某种程度上来说,像 Pocket 等稍后阅读工具或者 Evernote/为知笔记 等笔记手机工具,也能做到「阅读环境和交互的统一」,但是这些工具只提供环境,不提供「信息的自动收集」这个功能。RSS 阅读器会定时去检查信息源的 RSS 输出,发现更新后就呈现出来 —— 当然也可以用 IFTTT 一类的工具来监听信息源然后自动化地添加内容到 Pocket/Evernote 里,但这样稍显麻烦一些。
在 RSS 阅读器中,我可以对信息源进行分类整理,RSS 阅读器帮我进行定时的更新同步,我则定期打开 RSS 阅读器,选择某个类别一口气读完而不用在乎它是从哪个来源产生的。这种阅读体验很难在别的地方获得 —— 有点类似微博的 feed 流,但是社交平台上的内容质量相对还是太低了。

然而使用 RSS 阅读器会碰到一个问题,那就是一个信息源是否提供 RSS 格式的输出是由信息源自己控制的,它如果不愿意提供 RSS 输出,那么似乎就没有办法获得其中的信息了。当然实际上是有解决办法的,稍后再谈。
除了 RSS 阅读器,我还使用手机 App 「即刻」来接收资讯类信息。前文也说了,资讯类信息往往具有短时效性,且数量庞大,如果用 RSS 阅读器接收,很容易造成信息过载,对我来说,我只要知道每一天发生了哪些大事件即可,即刻上的「今天微博都在热议什么」和「一觉醒来世界发生了什么」很好地满足了我这个需求。
RSS 阅读器我用 Inoreader,再加上即刻,这就是我使用且仅使用的两个在线的信息收集工具。书籍阅读我要么用 Kindle,要么直接买实体书,书籍阅读笔记的收集属于知识的提炼部分,因此在本文不进行讨论。
Feed43: 从静态网站生成 RSS 输出
前文也说了,RSS 只是一种信息标准,信息源如果有提供 RSS 输出,那当然是最好的,如果没有,那么只要用一些方法将内容从信息源中「抽取」出来,然后按照 RSS 的格式组织好,不就生成了一个 RSS 输出结果吗?没错,任何一个可以公开访问的信息源,理论上都能转换为 RSS 输出,基本步骤就是「内容抽取-格式转换」两个步骤,由于 RSS 的格式是标准的,格式转换这一步没有太多难度,因此将一个网站的内容转换成 RSS 输出,主要的难度在内容抽取上。
最简单的一种情况是静态网站,所谓静态网站,是指访问的网页内容就是一个对不同的人来说内容不变的网页文件,这种网站上的内容访问不受限制,比如说不需要登录啊之类的,因此可以很简单地完成内容抽取这一步。而 Feed43 就是这样一个用来从静态网站中生成 RSS 输出的工具。
Feed43 的使用需要一点 HTML/CSS 的知识,稍微有点门槛,如果没有这方面知识的需要先了解一下。接下来以简书用户「计算士」的简书首页为例演示一下如何整个过程。
进入 Feed43 的页面后,点击「Create Feed」进入操作页。首先填入要处理的网页地址,在这里填入要解析的网页: http://www.jianshu.com/users/2e2954a2be81/latest_articles ,然后点击「Reload」来载入网页内容,如下图所示:
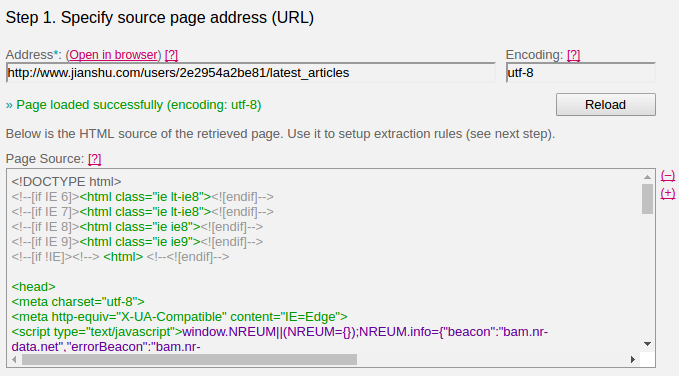
其实每一步 Feed43 都给出了简洁但友好的提示,如果懂 HTML/CSS ,按照提示一步一步进行就可以了。在载入网页内容后,Feed43 会要求填写提取规则,包含两部分
- Global Search Pattern: 用来定位内容的总体区域所在
- Item(repeatable) Search Pattern: 用来定位每一条内容的具体位置
提取规则会有一些简单的语法,可以通过点击界面上的小问号来查看了解。
提取规则填写好后,点击「Extract」可以看到提取内容,如果提取规则写得不对,那么提取结果会给出反馈,回去继续修改直到能正确提取即可。
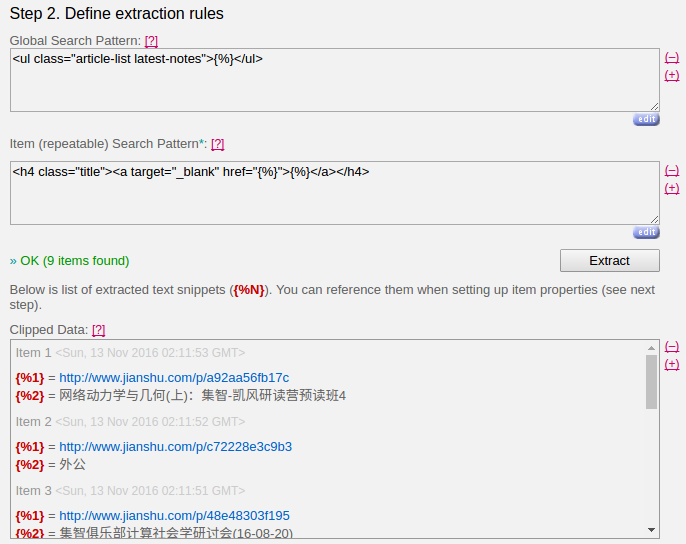
提取出内容后,再定义好 RSS 输出的内容,其实就是填写 title 是什么,url 是什么之类的。
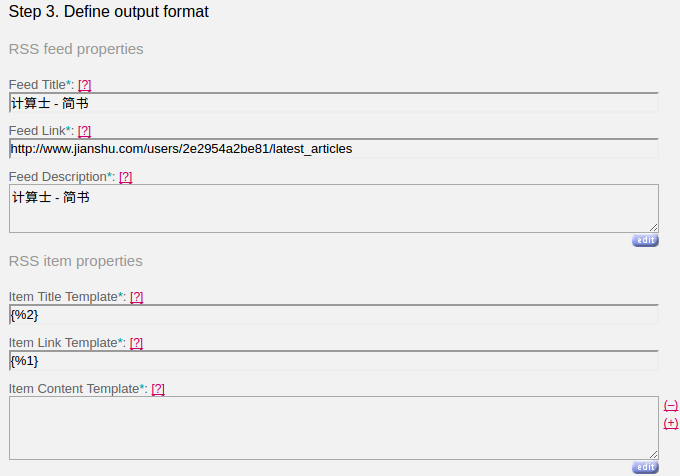
然后点击 preview 可以预览生成的 RSS 输出
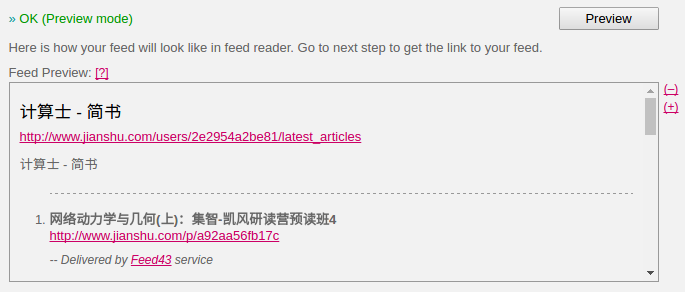
如果 preview 没有问题,Feed43 会生成可用的 RSS 链接,比如上述「计算士」的简书页面,生成的 RSS 链接为: http://feed43.com/5507461252042782.xml
微广场: 从微信公众号、知乎、简书、百度百家生成 RSS 输出
微信公众号是一个封闭的内容平台,对于想使用 RSS 阅读器来聚合信息的人来说可能是一个难以割舍的信息来源。而微广场对此提供服务,从微信公众号、知乎、简书等站点生成 RSS 输出,这样就可以把订阅的一堆微信公众号以及知乎上关注的很多专栏都整合进 RSS 阅读器里了。
简书在 Feed43 一节讲了,由于是静态网站,是可以用一些简单的工具来转换的,不过有现成的服务自然是乐得轻松了。微信公众号其实是一个很封闭的平台,不过好在后面搜狗提供了微信公众号的搜索,所以也有办法进行转换了。
由于免费用户只能订阅 10 个站点,我购买了一年的会员,除了没有订阅数量上限外,会员还能提交微广场没有收录的站点。
微博看看: 从微博用户的 feed 流生成 RSS 输出
「微博看看」原名「微博档案」,是一个微博备份工具,同时提供 RSS 输出。我原先在微博上关注了不少做机器学习、深度学习方面的微博用户,但他们的 feed 流经常被我关注的其他微博用户的 feed 流打乱,有了微博看看后我就取关了这些微博用户,在 RSS 阅读器里看他们输出的内容了,目前只对「爱可可-爱生活」老师的 feed 流做了转换。
Huginn: 从任意网站生成 RSS 输出

Huginn 是一个 Ruby 编写的自动化工具,在理念上类似 IFTTT 和天国的 Yahoo! Pipes,即进行事件的监听然后根据预先设定的规则自动化地进行后续操作。
Huginn 的 wiki 上列举了一些典型的使用场景,如:
- Never Forget Your Umbrella Again: 下雨提醒
- Adding RSS Feeds to Any Site: 为任意网站生成 RSS 输出
- Follow stock prices: 监听股票价格
在 Huginn 中,主要有 event 和 agent 两个概念,agent 类似 IFTTT 里的 channel,event 则是 agent 的输出。在 Huginn 中可以将一个 agent 的输出作为另外一个 agent 的输入,由此产生复杂的自动化操作。
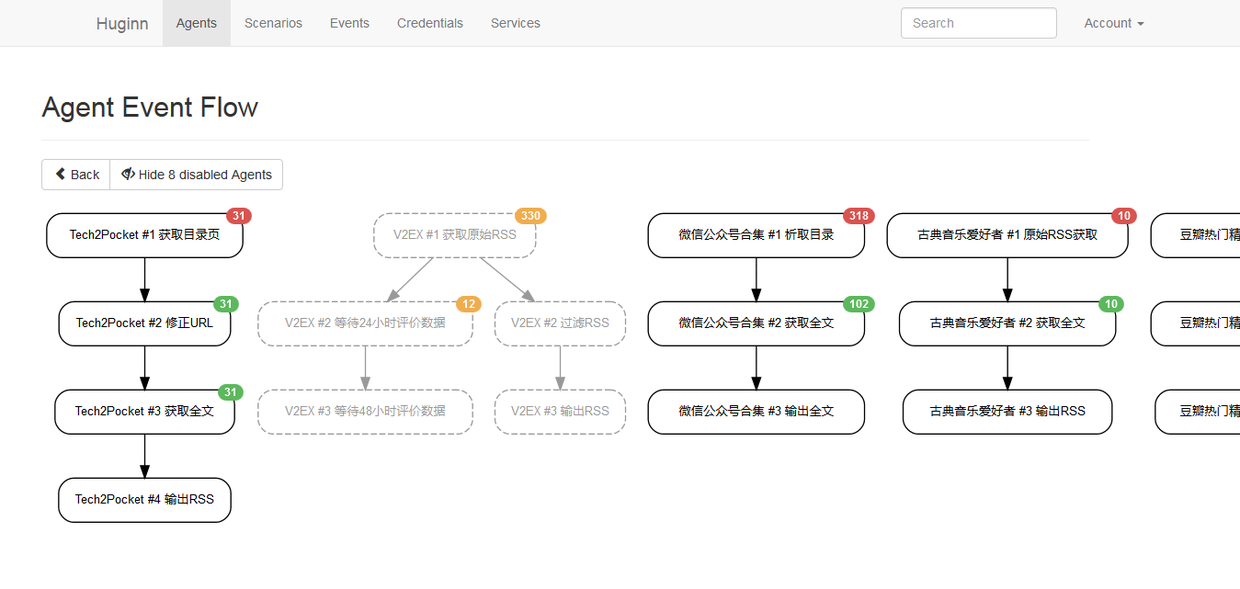
上图来自 Huginn:烧录RSS的神器 一文,该文对 Huginn 的使用做了很详细的介绍。
和 IFTTT 不同的是,Huginn 需要自己部署,很多细节需要自己定制,因此在使用门槛上会高很多。
目前我用 Huginn 来将 Google Scholar 关键词搜索结果输出为 RSS,这样我在 RSS 阅读器里就能看到我关心的一些深度学习的主题的论文更新情况了。此外,前文提到的提供微信公众号「微广场」,因为内容生产方的一些防护策略,可能会不稳定,替代方案是用 Huginn 从搜狗的微信公众号搜索结果中生成 RSS 输出。