
论文笔记:Ask Me Anyting: Dynamic Memory Networks for NLP
2018-11-10这篇论文的作者来自一家 AI 公司 MetaMind,因此虽然用了「Memory Network」这个概念,但在思路上和 FAIR 提出 Memory Network 的几个人都很不一样。按我的观点,这篇论文里的模型与其说是 Memory Network,不如说是 encoder-decoder + attention。
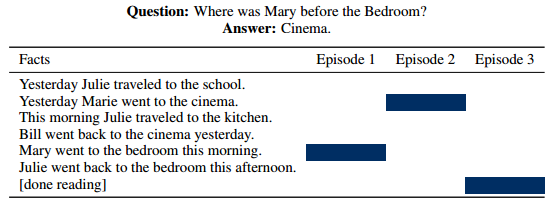
这篇论文同样是用来处理 QA 任务的,用的是 FAIR 公开的 bAbI 数据集。这个数据集所描述的场景,其实和 reading comprehension 更接近一点,先会有一段话进行描述,然后给出若干个问题,要求根据前面的描述来寻找答案,下面是一个例子:
I: Jane went to the hallway. I: Mary walked to the bathroom. I: Sandra went to the garden. I: Daniel went back to the garden. I: Sandra took the milk there. Q: Where is the milk? A: garden I: It started boring, but then it got interesting. Q: What’s the sentiment? A: positive Q: POS tags? A: PRP VBD JJ , CC RB PRP VBD JJ .
其中以 "I" 开头的句子就是描述性句子,被称为上下文(Context);"Q" 开头的句子则是问题,"A" 开头的句子是回答。在这个场景下,context 有一定的长度,要比 RNN 能处理的信息长度更大,但又是有限的。
与 14 年那提出的 Memory Network 模型和 Neural Turing Maching 模型不同的是,DMN 里没有使用外部的存储空间,而是直接用一个 RNN 的 encoder 对 context 进行编码,将这个过程中输出的 hidden state 作为 memory —— 所以我会认为这个模型更接近 encoder-decoder + attention 而不是 Memory Network 了。
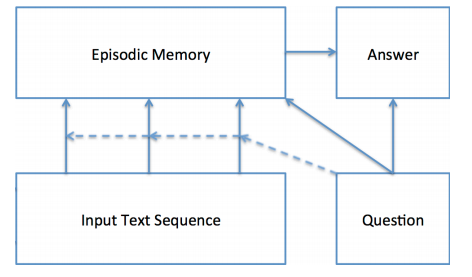
如上图所示,整个模型分为四个模块,和 Memory Network 里的 I/G/R/O 四个模块一一对应,但刚才也说了,其实这个模型和 Memory Network 并不是很像,所以作者为了对应上 Memory Network 的四个模块而作出类比,搞得有点不太好理解。图中的 Episodic Memory 模块并不对应 Memory Network 里的 memory 存储区域,非要说的话,应该是对应 Memory Network 里的 Response 模块,用来做结果的推理也就是 attention。
接下来我还是按我的理解来梳理这篇论文吧。
模型的 Input Module,其实就是一个 encoder,用来将 context 表示成 hidden state 形式的 "memory"。与 Memory Network 不同的是,各个 context 并不是分开处理的,而是串联成一个长的 sequence,然后喂给 RNN,然后只取每个 context 结束时输出的 hidden state。当然也有一些极端情况,比如说只有一个 context 的句子,这种情况下就直接输出每个 time step 的 hidden state 作为 memory。如下图所示:
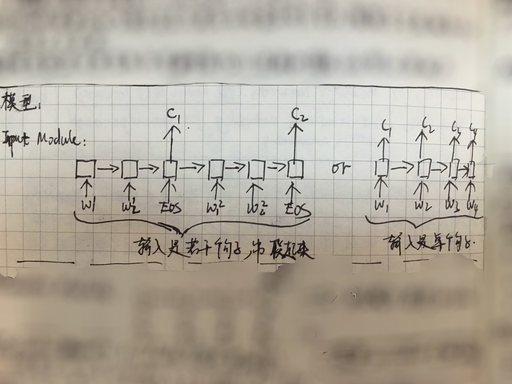
然后同样用一个 RNN encoder 对 quesiton 进行处理,不过这时只取这个 encoder 最后一个 time step 的 hidden state,作为这个 question 的表示。
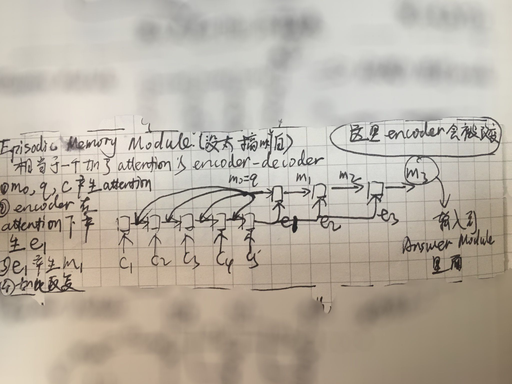
Episodic Memory Module 其实就是一个 attention 模块,用 question 在 Input Module 产生的 memory 上进行 attention。不过与普通的 attention 不同的是,这里的 attention 不是单纯地用 question 和 memory 进行內积算 softmax,而是再用一个 RNN encoder,将 Input Module 产生的 memory 依次输入到这个 encoder 中,并且每次都将 Question Module 的输出作为额外的信息参与计算,然后取这个 encoder 的最后一个 time step 的 hidden state 作为最后 Answer Module 里的 decoder 的 context vector。除了这点不同外,再就是这个过程可能会进行多遍,用每次计算出来的 context vector 输入到一个 decoder 里,用产生的 hidden state 再参与到 attention 中,这个迭代次数是认为设定的,在论文里作者就迭代了三次。如下图所示:
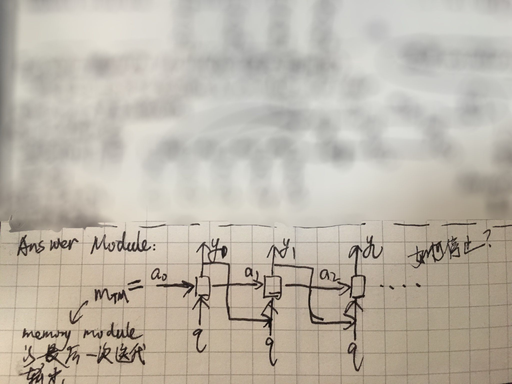
最后,将 Episodic Memory Module 的输出作为 context vector 输入到 Answer Module 的 decoder 里去,来生成最终的答案,这块比较简单,如下图所示。
比较有意思的是它里面那个 Episodic Memory Module 多遍迭代的结果,作者可视化后发现,第一遍的时候可能找到的是字面上相关的 context 句子,然后后面在迭代会慢慢定位到真正语义相关的 context 句子上,相当于是在做了推理。
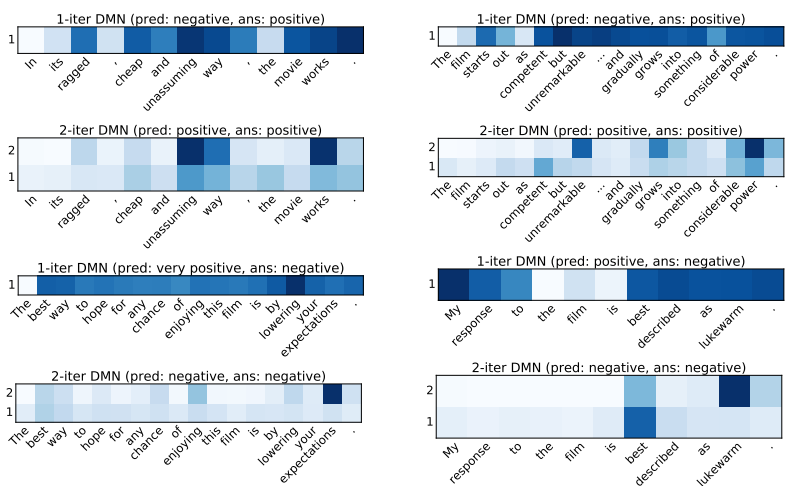
此外,作者还把模型用在了情感分析上,对句子中词的 attention 结果,在迭代过程中的变化也展现出了类似的现象。
以上。