
论文笔记:Decoupled Neural Interfaces using Synthetic Gradients
2018-11-10这篇论文是 DeepMind 在 2016 年 8 月 18 日发布的,最初是在智能单元上看到这个消息的,觉得挺有趣的,就去读了一下。
这篇论文干了什么呢?它在现有的神经网络模型基础上,提出了一种称为 Decoupled Neural Interfaces(后面缩写为 DNI) 的网络层之间的交互方式,用来加速神经网络的训练速度。
作者在开篇指出,在神经网络模型训练中存在几个问题
- Forward Locking: 前一层没有用输入完成计算,后一层无法进行根据输入进行计算
- Update Locking: 如果一个网络层依赖的层没有完成前馈计算,该层无法进行更新
- Backward Locking: 如果一个网络层依赖的层没有完成反向传播,该层无法进行更新
刚看到这说不定会想你这不是废话吗,前一层没计算好后一层怎么计算怎么更新?哎,作者表示我就是不信这个邪我就是要上天和太阳肩并肩啊!为什么呢,因为在一些情况下,神经网络的这种计算模式会带来一些问题,这些情况包括:
- 由多个异步模块组成的复杂的系统(这个不懂……)
- 分布式模型,模型的一部分共享给多个下游客户端使用,最慢的客户端将会成为模型更新速度的短板
所以呢,作者就想办法把这种训练时层与层互相依赖的限制干掉咯。
第一个想法,是干掉 Update Locking 和 Backward Locking,让网络的每一层在完成前馈计算后能马上计算出残差,然后立即进行该层的参数更新,而不用等待后一层的前馈计算和误差反向传播。这个是怎么做到的呢?办法就是, 增加一个额外的模型 ,去根据当前网络层的输出去预测其残差,并用预测到的残差去计算梯度,这个实际梯度的估计值,被称为「合成梯度(synthetic gradients)」。
先来看看传统的误差反向传播(Backpropagation, BP)算法,我们假设一个有 N 层的神经网络,其第 i 层的激活值即输出为 \(h_{i}\) ,那么对第 i 层,其参数更新式子为:
\[\begin{array}{rcl} \theta_{i} &\leftarrow& \theta_{i} - \alpha\delta_{i}\frac{\partial h_{i}}{\partial \theta_{i}} \\ &\leftarrow& \theta_{i} - \alpha\delta_{N}\frac{\partial h_{i}}{\partial \theta_{i}}\cdot \prod_{j=0}^{N-i-1}\frac{\partial h_{N-j}}{\partial h_{N-j-1}}\end{array}\]
可以看到,需要依赖后面所有层的激活值的计算。作者的思路就是只利用当前层的激活值 \(h_{i}\) 去得到当前层的残差 \(\delta_{i}\) 的估计值 \(\hat{\delta_{i}}\):
\[\begin{array}{rcl} \delta_{i} &\sim& \hat{\delta_{i}} \\ &=& M_{i+1}(h_{i})\end{array}\]
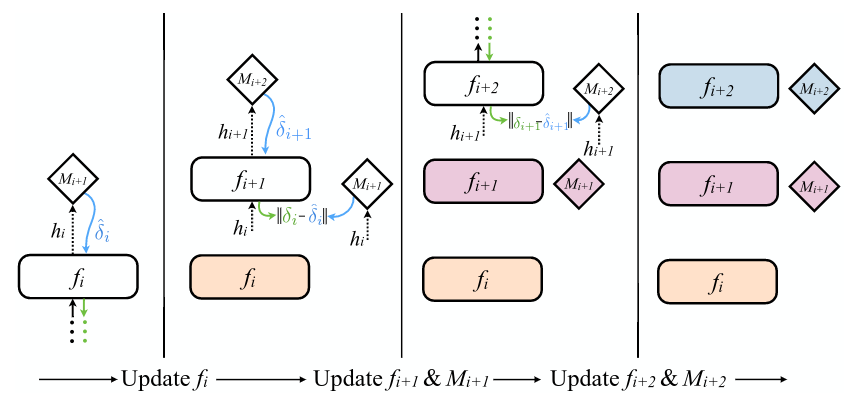
但是可想而知,在初始的时候,这样一个「额外的模型 M」所给出的残差估计值肯定是与实际的残差有很大的偏差的,那么怎么办呢?办法就是用每一层的实际的残差去训练这个额外的模型 M —— 不过这样不就将 BP 的过程转移到另外一个模型里去了么,这不是耍流氓嘛!不过作者在这里又使用了一个技巧,将 BP 过程彻底干掉了。
我们都知道,所谓误差反向传播,是先计算出最后一层的残差,然后用最后一层的残差去计算倒数第二层的残差,依次类推,故称「误差反向传播」。如果在训练模型 M 时依然遵照这个流程,毫无疑问 Update Locking 和 Backward Locking 依然存在,所以作者在计算每一层的“实际残差”时,用的是后一层的“合成残差”,而合成残差的计算是可以立即计算的。这里实际上又做了一次近似,也就是:
\[\delta_{i} = \hat{\delta}_{i+1}\frac{\partial h_{i+1}}{\partial h_{i}}\]
这样用这个近似的 \(\delta_{i}\) ,去评估模型 M 给出的残差估计值 \(\hat{\delta_{i}}\) ,并用两者之间的误差去更新模型 M。由于最后一层是能得到真正的残差的,所以最后一层的模型 M 能较快得到训练,随着最后一层的模型 M 被训练的越来越好,它所估计出的 \(\hat{\delta_{i}}\) 也能越接近真实的 \(\delta_{i}\) 。如下图所示:
再进一步地,作者表示,利用 DNI 的思想,去预测每一层的输入也是可以的,这样就把 Forward Locking 也去掉了。基本思想和合成梯度是一样的,不同之处在于预测每一层的输入时只用到第一层也就是输入层的输入:
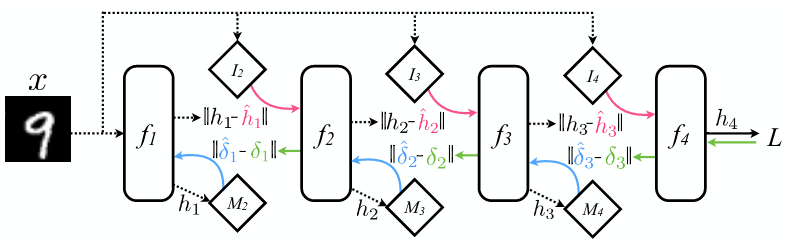
这样 Forward Locking、Update Locking 和 Backward Locking 都被去掉了,通过适当的设计,整个训练可以被很好地并行化、异步化了。
DNI 的思想除了用在前馈神经网络上,也可以用于循环神经网络(Recurrent Neural Network, RNN)的训练上面,因为 RNN 在时间维度上展开后,其实就相当于是一个前馈神经网络了。而且由于应用 DNI 的模型,最多只有两层的网络层依赖,那么在用于 RNN 训练时,可以不用将 RNN 完全展开,而是可以以两个 time step 为最小单元进行展开,即一次只展开两个 time step,这样在存储上的消耗也可以被降低。
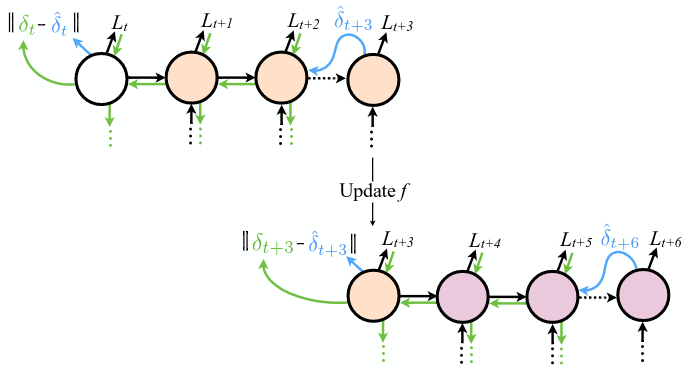
来看看作者的牛皮
Although we have explicitly described the application of DNI for communication between layers in feedforward networks, and between recurrent cores in recurrent networks, thereis nothing to restrict the use of DNI for arbitrary network graphs. The same procedure can be applied toany network or collection of networks, any number of times.
以上就是 DNI 的理论部分,实际上还有很多东西没有讲清楚,比如:
- 那个额外的模型 M 的具体细节?
- 增加了额外的模型 M ,相当于增加了参数数量,是不是更容易过拟合了?
作者首先在 MNIST 和 CIFAR-10 两个数据集上测试了 DNI 方法和 BP 方法之间的训练效果(只去除 Update Locking 和 Backward Locking)
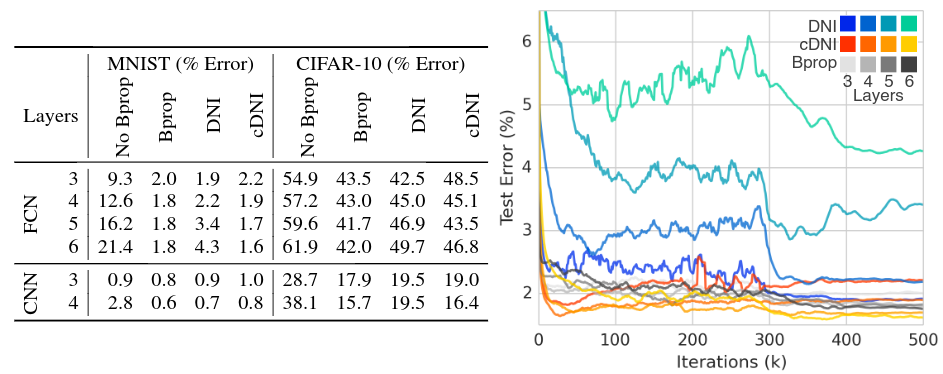
需要说明的是,这里用的模型(FCN 和 CNN)层数都不多,实验分别使用了 3-6 的层数,见上图中右侧部分,从该图来看,使用 DNI 的训练方法在训练速度和训练效果上并没有什么优势。这个实验只是表明,使用 DNI ,模型 能够被训练 。
第二个实验是这样的:对一个四层的前馈网络,以随机的顺序来更新每一层,并且每一层在被选中都是有概率的。在这样的情况下,模型依然是可以被训练的。
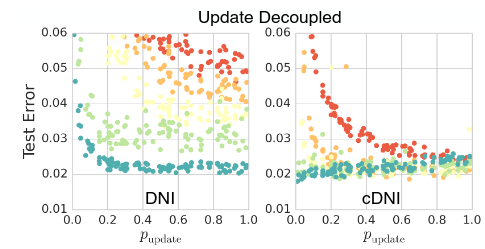
不过明显能看出来,概率值越大,收敛是越快的,最后在迭代次数达到 50w 次时,不同的概率都达到了接近的精度(2% 的误差),不过一个四层的网络,真的不是过拟合了么……
第三个实验在第二个实验的基础上,加上了 synthetic inputs ,也就是把 Forward Locking 去掉了,从结果上来看,和第二个实验差不多的样子。
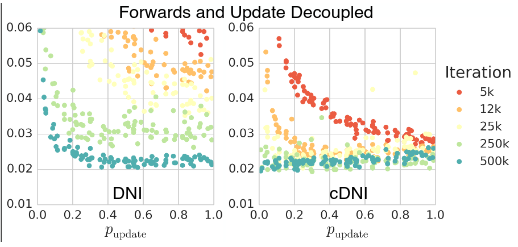
最后在 RNN 上进行了三个实验,分别是:
- Copy: 读入 N 个字符,然后将这 N 个字符原样输出,有点类似 char-level language model 和 autoencoder。
- Repeat Copy: 读入 N 个字符,以及一个表示重复次数的数字 R,然后重复输出 R 次这 N 个字符构成的序列。
- char-level language modeling: (持续地)读取一个字符,并预测下一个字符。
结果如下图所示:

上图中 Copy 和 Repeat Copy 两栏中的值表示建模的最大序列长度,越大越好;Penn Treebank 一栏表示语言模型的困惑度(Perplexity,这里用 bits per word 进行度量),越小越好。从实验结果上来看,在 Copy 和 Repeat Copy 任务上,使用 DNI 的模型能建模更长的序列。