
论文笔记:Learning Phrase Representation using RNN Encode-Decoder for Statistical Machine Translation
2018-11-10作者在这篇论文中提出了一种新的模型,并用来进行机器翻译和比较不同语言的短语/词组(phrase)之间的语义近似程度。这个模型由两个 RNN 组成,其中一个(Encoder)用来将输入的序列表示成一个固定长度的向量,另一个(Decoder)则使用这个向量重建出目标序列 —— 在机器翻译任务里,可以认为 Encoder 产生的向量是输入文本的 语义表达 ,而 Decoder 则根据这个语义表达产生目标语言的文本。
模型结构如下图所示
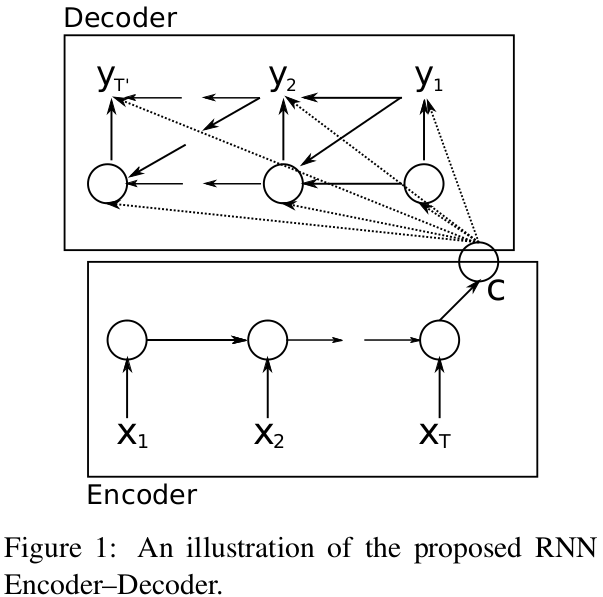
这个结构其实和 "Sequence to Sequence Learning with Neural Networks" (后面简称 "Sequence to Sequence")里提出的结构是非常相似的,见下图:
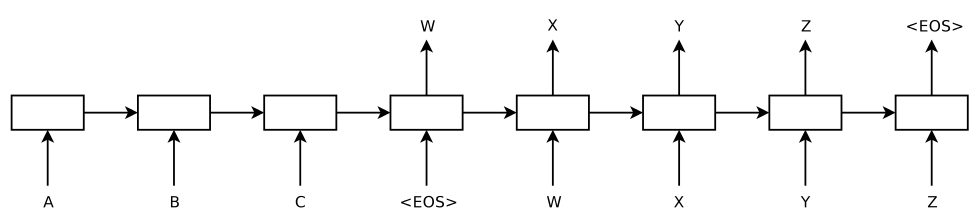
"Sequence to Sequence" 这篇论文的作者自己也表示 "Our approach is very similar to Cho et al" 。
两种结构的不同之处在于,Encoder 输出的向量,在后者这里只用来作 Decoder 的第一个 time step 的输入,而在 Cho 的这篇论文里,它是要在 Decoder 的每一个 time step 中都参与计算的。即在 "Sequence to Sequence" 中,Decoder 中第 t 个 time step 时计算输出的式子为
\[P(y_{t})=f(h_{t}, y_{t-1})\]
而在 Cho 的论文中,则是
\[P(y_{t})=f(h_{t}, y_{t-1}, c)\]
其中 \(h_{t}\) 表示第 t 个 time step 时 Decoder 的内部状态(RNN 单元的 "memory"),\(c\) 表示 Encoder 输出的向量。
再有一点不同是,Cho 在这篇论文中提出了 GRU 这种 LSTM 的简化版本单元结构,使用的 RNN 也是以 GRU 而非 LSTM 组成的。对 LSTM、GRU 的细节这里就不深入了,反正 Cho 自己还有一篇论文就是比较 LSTM 和 GRU 的各自优缺点的,到时候也读一读记录一下笔记什么的。
Cho 的 Encoder-Decoder 模型中,Encoder 的行为比较简单,重点在 Decoder 上。
Decoder 中 t 时刻的内部状态的 \(h_{t}\) 为:
\[h_{t}=g(h_{t-1}, y_{t-1}, c)\]
该时刻的输出概率则为:
\[P(y_{t}|y_{t-1}, y_{t-2},...,y_{1}, c)=f(h_{t}, y_{t-1}, c)\]
模型训练时则去最大化给定输入序列 x 时输出序列为 y 的条件概率:
\[\arg\max_{\theta}\frac{1}{N}\sum_{n=1}^{N}logP_{\theta}(Y_{n}|X_{n})\]
这个模型用来做机器翻译是很自然的,除了机器翻译外,作者还用这个模型来得到英语 phrase 和法语 phrase 之间的语义近似值(或说相似性),方法是用大量的英语和法语的 phrase pair 进行训练,每个 pair 在训练时最后都会有概率输出,就用这个概率值作为这个 pair 对的 score ,并在整个训练过程中更新,最后得到一张记录很多 phare pair 近似值的表,这个表可以在其他的统计机器翻译(Statistical Machine Translation, SMT)系统中使用 —— 比如要将某个英语 phrase 翻译成法语 phrase 时,可以从表中找到与该英语 phrase 最接近的 K 个法语 phrase 作为候选。
在机器翻译上,作者用 Moses (一个 SMT 系统) 建立了一个 phrase based 的翻译模型作为 baseline system ,然后对比了以下四个模型的 BLEU 值
- Baseline configuration
- Baseline + RNN
- Baseline + CSLM + RNN
- Baseline + CSLM + RNN + Word penalty
所谓 BLEU 呢,是 BiLingual Evaluation Understudy 的缩写,是业界用来评估一个机器翻译系统水平的基准,如果遇到做机器翻译的上去问问 “你们的系统 BLEU 是多少” ,绝对会被认为你是专业人士,所以不妨记一下这个词 :) 。不过实际上 BLEU 和人工评价相差甚远,而且对于一些小的错误非常敏感,Yvette Graham 等人在 NAACL 2016 上专门有一篇长论文(Achieving Accurate conclusions in Evaluation of Automatic Machine Translation Metrics)讨论这个事情,这篇论文受到了很大的重视。
回归正题,四种不同的模型的 BLEU 值如下表所示:
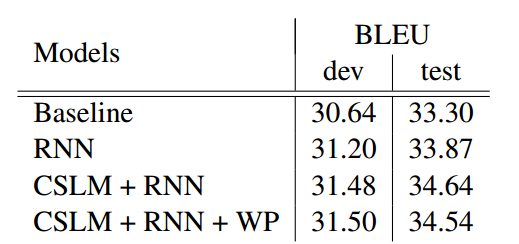
其实也不见得比传统方法要好多少。当然据我所知, Encoder-Decoder 这个模型还是挺受重视的,如果我没记错的话,上次在 QCon 上看到阿里的跨境电商翻译系统应该是用上了 Encoder-Decoder 结构(不想误导,他们还有专业团队进行人工翻译)。
phrase pair 打分的结果如下:
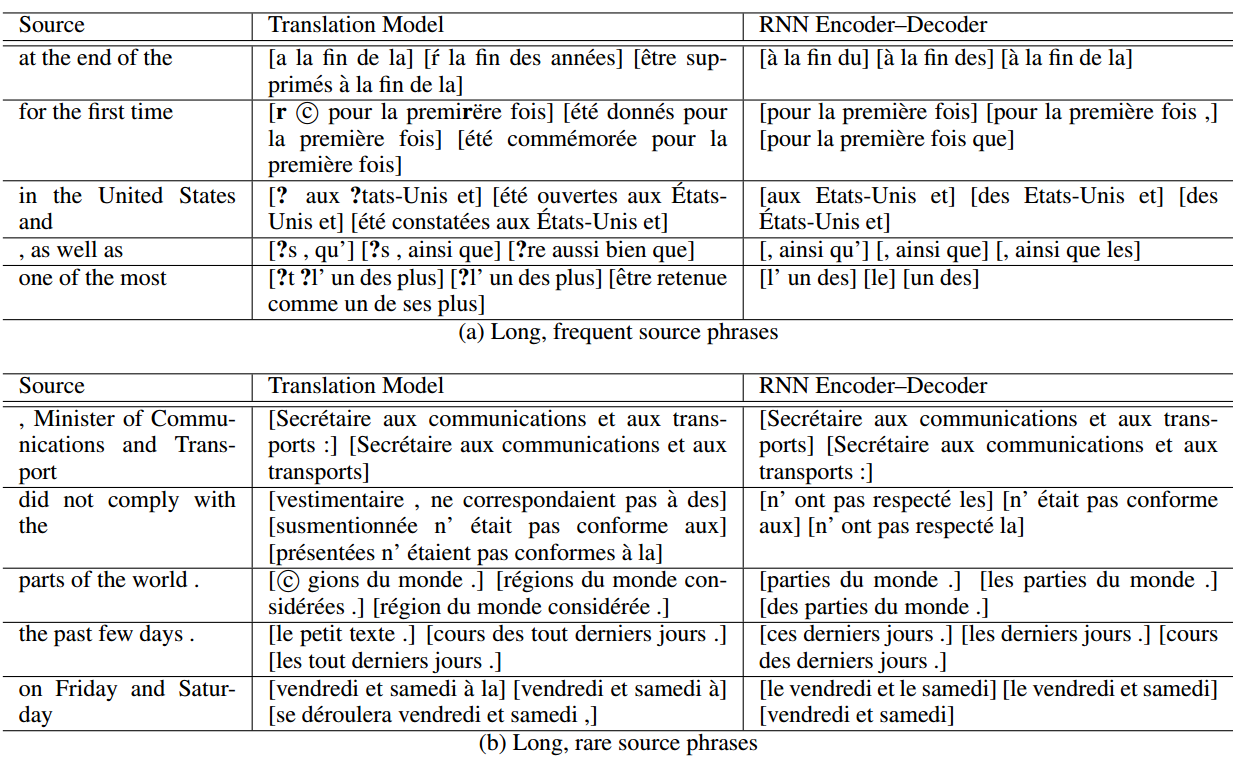
其中第一栏是输入的英语 phrase ,第二栏是用传统的模型得到的最近似的三个法语 phrase,第三栏是用 Encoder-Decoder 模型得到的最近似的三个 phrase。
就我对这篇论文的理解来说,应该是这样的。结尾再对计算两个序列之间的相似性这件事情说说自己的想法,在这件事情上,作者只是在训练过程中得到这样一个额外的、静态的结果,最后得到的那张表,其中包含的 phrase 是确定的、有限的,姑且认为其中的 phrase 都是粒度比 sentence 更细的合法单元,但实际上可以把 Decoder 的输出看成一个搜索空间,在给定 任意 输入序列的时候,用输出序列在这个空间里确定搜索路径,这条路径上每一条边都是有置信度(概率)的,这样就可以直接得到一个条件概率来表征连个序列之间的相似程度,好处是可以处理任意的 sequence pair,这对实际问题应该会有帮助。当然这个想法可行性有待验证就是了。