
论文笔记:Sequence to Sequence Learning with Neural Networks
2018-11-10三位来自 Google 的作者在这篇论文中提出了一种以两个 RNN 组合方式构成的网络结构,用来处理英语到法语的翻译问题,并且认为对于传统的深度神经网络(Deep Neural Network, DNN)不能处理的输入和输出都是变长序列的问题,这种模型都能很好地进行处理。
自 2006 年 Hinton 掀起深度学习这股浪潮,联结主义强势回归到现在已经有 10 年了,这 10 年里,深度学习已经在图像和语音两大领域取得了卓越的成就。然而大部分的深度神经网络仍然需要输入和输出的大小固定不变,并将一层一层不同类型的网络层组合在一起,通过巨量的数据、更有效的优化方法和训练技巧来达到目的,而这里的 "输入和输出的大小固定不变" 是一个很大的限制,比如说我们的语言、文字,天然就是变长的序列,这些网络结构要处理的话就必须要在核心模型之外在加上一些额外的处理。举个例子,图像识别中的图像一般也不是固定大小的,输入前一般都需要进行预处理将图像规整到同一尺寸。
面对这一问题,一个很自然的方法就是使用循环神经网络(Recurrent Neural Network, RNN),这是一种在空间结构上非常简单的模型,在一些不太复杂的问题上,甚至只需要三层结构就足够了,如下图所示(配图来自 Elman 的 《Find Structure in Time》)
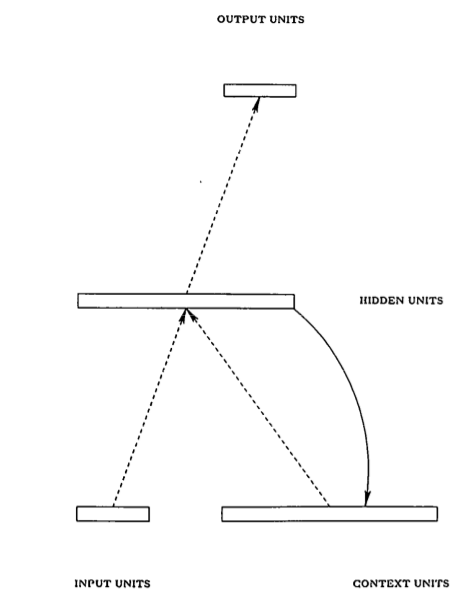
相比传统的前馈神经网络(Feedforward Neural Network, FNN),RNN 的独特之处在于其隐藏层的一个环状结构,这个结构相当于能够缓存当前的输入,并用之参与下一次的计算,这样就隐式地将 时间信息 包含到模型中去了,在输入变长序列时,可以序列中的最小单元逐个输入。RNN 虽然在空间结构上可以很简单,但在进行训练时通常需要在 时间维度 上展开(unroll),所以可以认为它是一个在时间维度上的 DNN,于是 DNN 训练中会出现的 gradient vanish (梯度消失)也会出现,直观上可以将其理解为 "记忆的衰退",换句话说, RNN 只能 "记住" 短期的信息。1997 年 "长短期记忆单元(Long Short-Term Memory, LSTM)" 被提出来解决这个问题,而本文提出的模型就是利用了 LSTM 的优点。
虽说 RNN 能用于处理变长序列,但具体要怎么做呢?最早提出 RNN 之一的 Elman 做过的一些实验是这样的: 将序列中的元素逐个输入网络,并预测下一时刻的输入,比如一条句子逐个字符输入网络,并在输入第 n 个字符时预测第 n+1 个字符。这种方式虽然能处理变长的输入序列,但得到的输出序列却是和输入序列长度一样的,限制仍然还在。
一种办法是在输出时增加一个 "空白" 的输出候选,然后在每次输出时取每一种可能输出结果的概率,得到一张路径网络后用类似 beam search 的方法来组装起真正的输出,由于 "空白" 输出的存在,最后得到的非空白输出序列的长度就变成可变的了。语音识别和一些 OCR、手写识别是这么做的,效果也还不错。
而作者提出的方法是将两个 RNN 组合起来,以更加灵活地处理变长输入序列和变长输出序列。其模型结构如下(注意,这是一个已经 unroll 的网络结构)
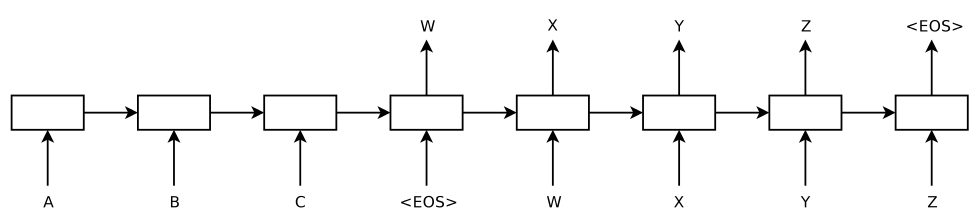
模型的左侧(到输入为 <EOS> 为止)是一个 RNN 在输入序列 "ABC<EOS>" 上的展开,右侧是在输出序列 "wxyz<EOS>" 上的展开,其中 <EOS> 是一个表示序列结束的特殊符号。功能上,第一个 RNN 用来将输入序列映射成一个固定长度的向量,这个 "固定长度的向量" 即是 RNN 中间隐藏层所缓存的对整个输入序列的 "记忆",我们可以说它表示了输入序列的语义;然后用第二个 RNN ,来从这个向量中得到期望的输出序列。
除了这个特殊的模型结构之外,再就是用 LSTM 来保留 一定程度 的长期记忆信息,并且作者表示复杂的网络结构(更多的参数)具有更强的表达能力,因此每个 RNN 用的都是 4 层的 LSTM, 参数两多达 380M, 也就是 38 亿 —— Google 的朋友们你们真是站着说话不腰疼啊,38 亿参数的模型,一般人哪来这么多数据喂饱这个大胃王,哪来那么强劲的机器来训练……
再就是,作者说将输入序列倒序后,效果得到了显著地改善,BLEU 从使用该方法之前的 25.9 上升到 30.6,然而自己也对其原因表示不太清楚,只作出了一些猜想(也就是说,并无明确的理论依据)。
原文中,作者对这个技巧的解释如下
While we do not have a complete explanation to this phenomenon, we believe that it is caused by the introduction of many short term dependencies to the dataset
以及
By reversing the words in the source sentence, the average distance between corresponding words in the source and target language is unchanged. However, the first few words in the source language are now very close to the first few words in the target language, so the problem's minimal time lag is greatly reduced.
模型训练时,以最大化条件概率为目标,也就是说,其目标函数为
\[\frac{1}{|S|}\sum \log P(T|S)\]
而在模型训练好后,用于实际的预测时,则也采用了简单的 beam search 方法,即在模型参数确定的情况下,对输入序列 \(S\) ,按下面的式子求解输出序列
\[\hat{T} = \arg\max_{T}P(T|S)\]
下表是与其他模型在机器翻上的的效果对比,其中上面两行是其他模型的效果,下面六行是作者模型在不同参数设置时的结果。
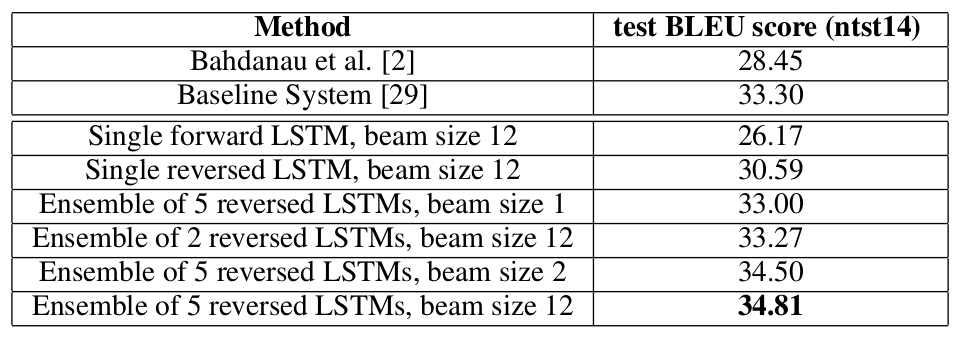
此外作者还尝试将自己的模型与传统的 SMT 系统进行结合,效果显著, BLEU 最好的达到了 37,超过 baseline system 4 个点。

sequence to sequence 模型被提出后,由于其灵活性,受到了广泛的关注,我个人是很喜欢这个模型中的想法的。然而现在流行的几个开源库对 sequence to sequence 模型的支持仍然不太理想,它们都要求在模型定义时就将输入序列的最大长度和输出序列的最大长度确定,对于长度不足的,则要用特殊符号进行填充,并在模型内部或外部做一些特殊处理。比如用 Python 的深度学习框架 Keras 来实现一个弱化版的 sequence to sequence 模型,可以这样:
# coding: utf-8 """Sequence to Sequence with Keras 1.0""" from keras.models import Sequential from keras.layers.core import Dense, RepeatVector from keras.layers.recurrent import LSTM from keras.layers.wrappers import TimeDistributed def build_model(input_size, max_output_seq_len, hidden_size): """建立一个 sequence to sequence 模型""" model = Sequential() model.add(LSTM(input_dim=input_size, output_dim=hidden_size, return_sequences=False)) model.add(Dense(hidden_size, activation="relu")) # 下面这里将输入序列的向量表示复制 max_output_seq_len 份作为第二个 LSTM 的输入序列 model.add(RepeatVector(max_output_seq_len)) model.add(LSTM(hidden_size, return_sequences=True)) model.add(TimeDistributed(Dense(output_dim=input_size, activation="linear"))) model.compile(loss="mse", optimizer='adam') return model
上面这段代码,从模型定义上,只对输出序列做了最大限制,但训练数据集中 不允许出现不同长度的输入序列 ,实际上不同长度的目标输出序列也不被允许。希望这种情况在将来能够有所改善,当然啦,不行的话可以自己用 Theano 写嘛~