
ZMonster's 每日摘要 2020-11-16
2020-11-16尝试在本周每天写一个当日摘要发到博客上,对于当日摘要要写些什么东西,暂定会有「笔记」和「时间」两块,不过我的想法随时可能会变,也许会在之后的几天产生新的想法,这一周时间一来是想确认一下我每天可以输出什么东西,然后也看一下自己是否能坚持这种写作方式吧。
笔记
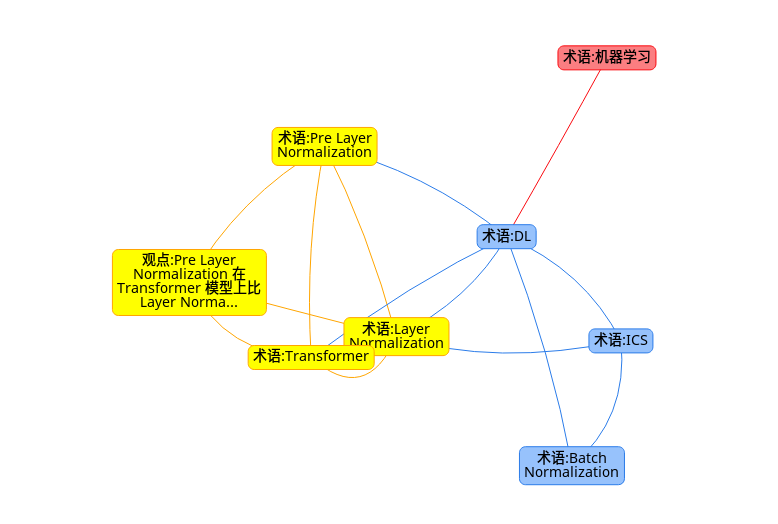
术语: 内部协方差漂移(Internel Covariate Shift, ICS)
指深度学习模型在训练过程中,每次迭代后因为参数被改变导致模型输出的分布发生变化,导致训练过程为了适应不同的模型输出分布而训练收敛慢的问题。
术语: Batch Normalization
指在训练时用一个 batch 的数据计算均值和方差后将每层输出归一化到标准正态分布,以解决内部协方差漂移使得模型训练慢的问题,实际做法中为了保持每一层的表达能力,在归一化到正态分布后又会通过两个可学习参数(均值和方差)再变换到一个非标准正态分布上,所以实际上内部协方差还是会在漂移,后来也有研究说这种做法会使得 loss 曲面更加平滑所以有效。
术语: Layer Normalization
指在训练时用一个样本在每层的输出单独计算均值和方差后将这个输出归一化到标准正态分布上的做法,据说也能缓解内部协方差漂移问题从而提高模型的收敛速度。Transformer 系的模型都使用了 Layer Normalization,下图中的 Norm 指的就是 Layer Normalization。
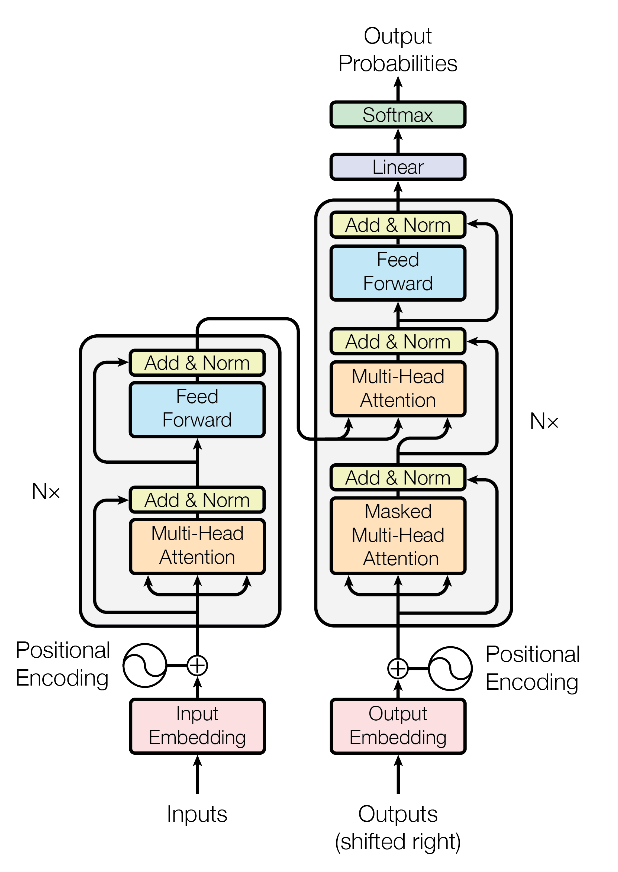
术语: Pre Layer Normalization
在 Transformer 之类的模型中,输入经过 self-attention 后,经过一次线性变换后才做 Layer Normalization 处理,所谓 Pre Layer Normalization 是指在类似的情况下,在线性变换之前就进行 Layer Normalization 处理。提出这一方法的论文1声称它这一简单的修改就能对模型有提高。
观点: Pre Layer Normalization 在 Transformer 模型上比 Layer Normalization 好
论据:
- 从理论上分析,先做线性变换再做 Layer Normalization 的问题在于,线性变换的参数矩阵如果是从一个各向同性的高斯分布中采样初始化的话,即使输出不是零均值的,经过变换后也会变成零均值,这会使得 Layer Normalization 的效果变差
- 在 LM1B 数据集上,改成使用 Pre Layer Normalization 的模型比原版模型的 PPL 低 0.3(38.341->38.002)
个人看法
- 实际上到目前为止 Batch Normalization/Layer Normalization 起作用的原因也并没有研究很清楚,所谓 ICS 问题,在 Batch Normalization 上其实不太站得住脚,倒是让 loss 曲面更加平滑这个理由更好理解一些,所以在 Transformer 中线性变换在前而 Layer Normalization 在后会导致效果变差,可能并不是一个很强的理论分析
- 再说效果,PPL 只降了区区 0.3 不到 1%,这也不是一个很强的改进,再说了 LM1B 是个啥数据集?不在 GLUE 上跑一跑难以服众啊
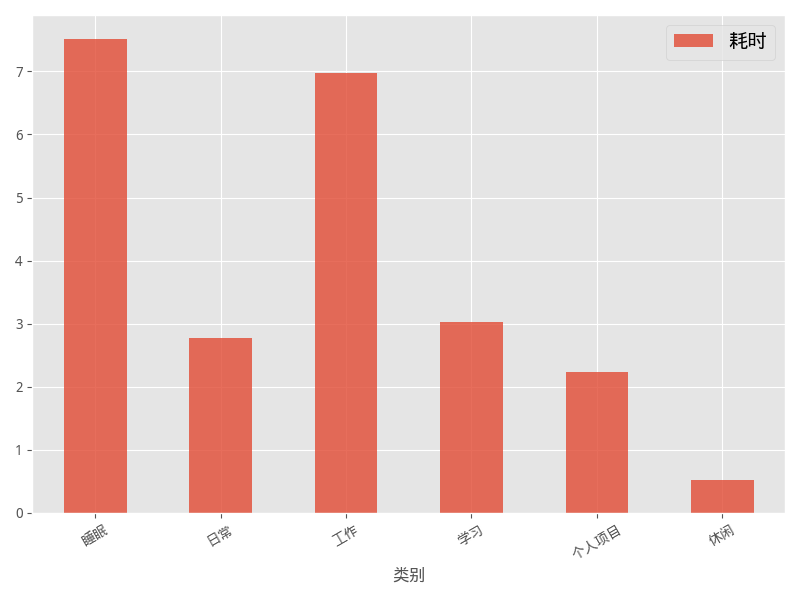
时间
脚注:
Is Batch Norm unique? An empirical investigation and prescription to emulatethe best properties of common normalizers without batch dependence