我的年度总结所使用到的数据分析和可视化工具
2024-01-18目录
两年前我写完《我的2021》后有些朋友问我用到了什么工具和方法,前阵子写完《我的2023》后又有一些朋友询问,所以就来简单写一下好了。
数据的获取
在两篇年度总结中,我用到了这么一些数据
- 日记文本
- 工作日志文本
- org-mode clock 记录
- 微信聊天记录
- B站观看记录
其中日记文本和工作日志文本都没有什么好说的,都是我用 org-mode 手工记下来的,这里只简单展示一下这两者的内容结构
工作日志是一个「年-月-日-具体记录」的四级结构
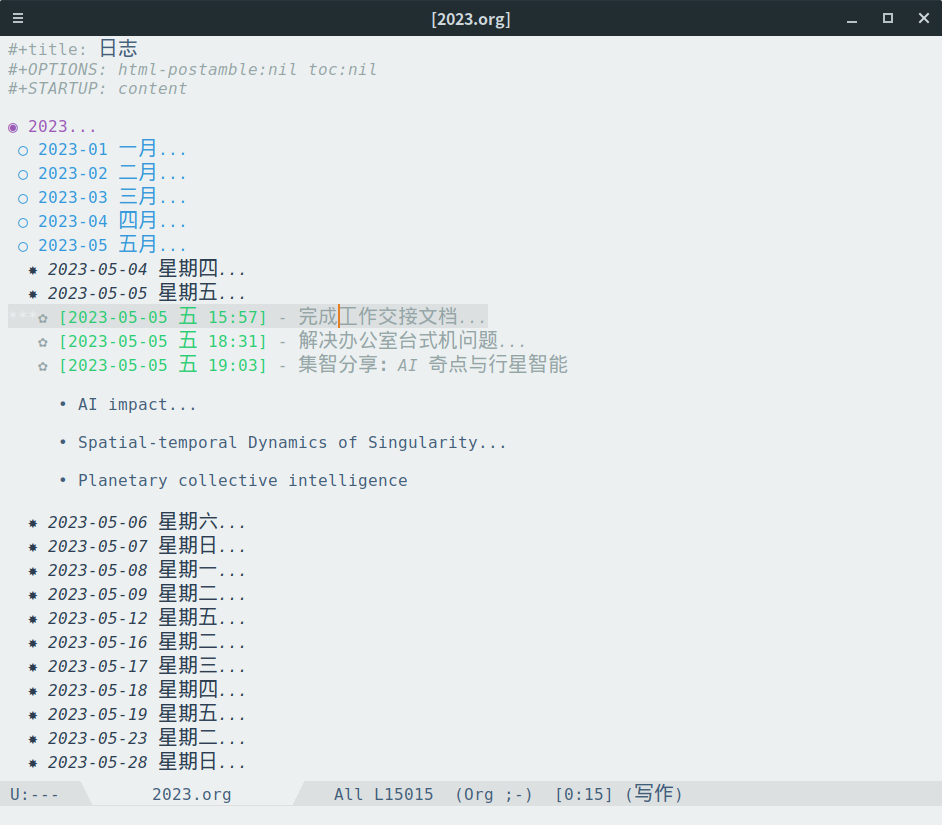
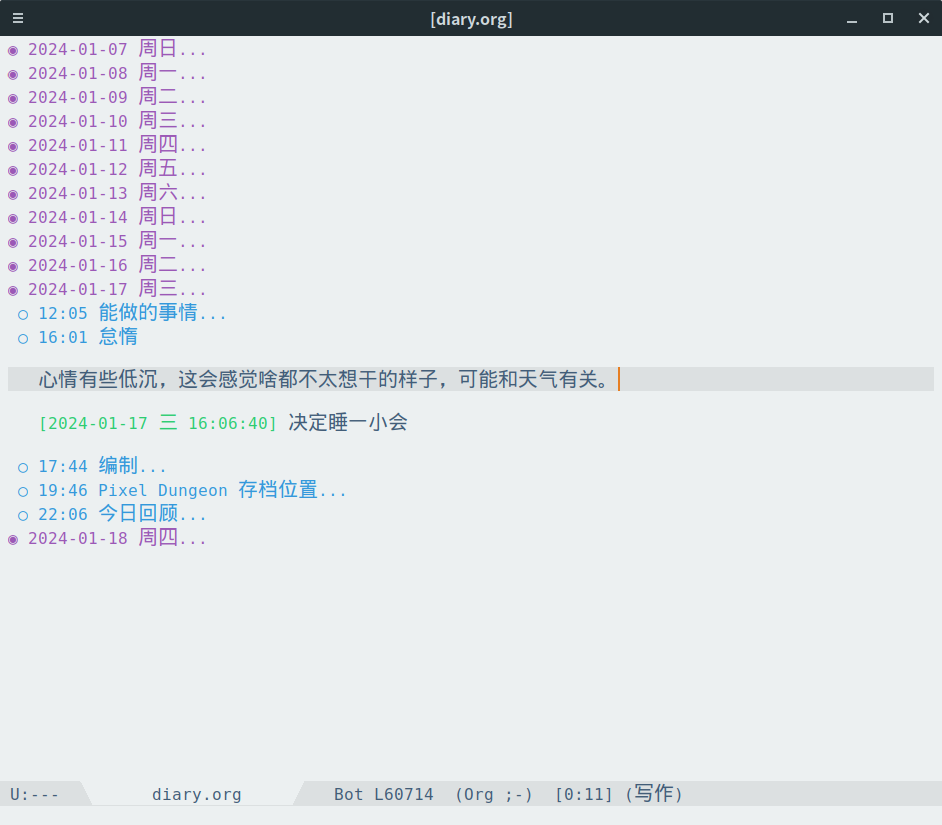
日记是一个「日-具体记录」的两级结构
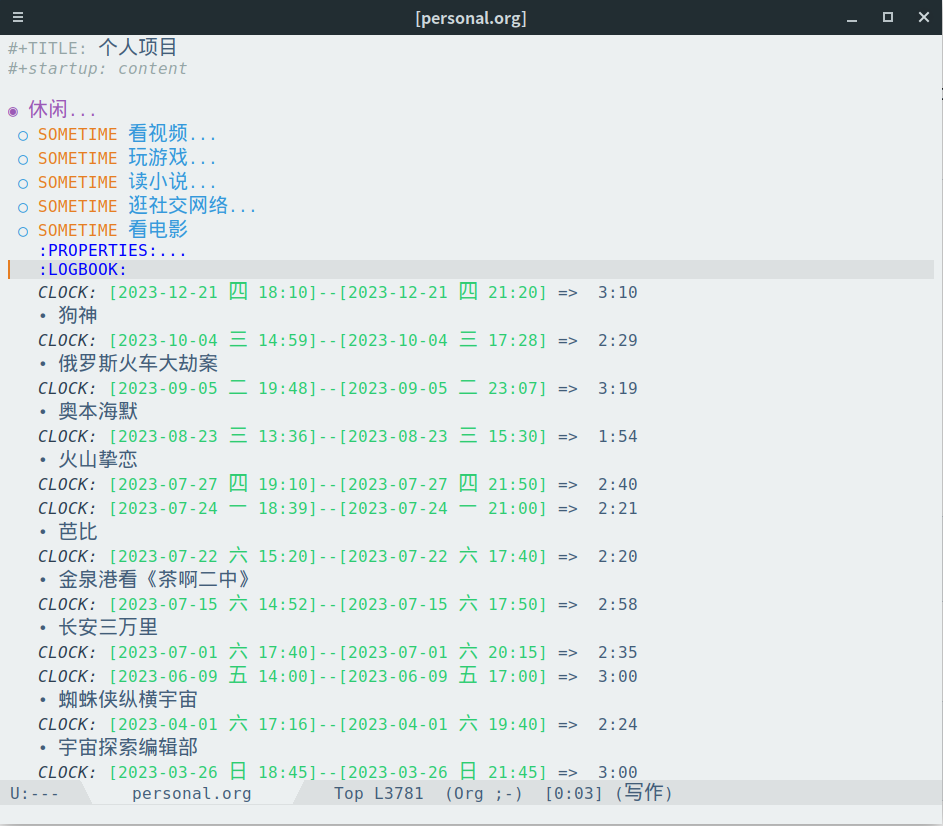
org-mode clock 记录也是使用 org-mode 产生的,这个在《我的生活记录经验及个人工具与方法》这篇文章中也有提过,每当我执行 org-clock-in 或者 org-clock-out 后就会自动在对应任务下的 LOGBOOK 下自动地新增记录,如下图所示:
然后是微信聊天记录,我目前使用 EFB 来将微信消息转发到 Telegram,而 Telegram 是有接口能导出历史消息的,其 PC 桌面端也能直接将历史消息导出。其他的微信聊天记录导出方式我没有了解过。
B站的观看记录,我自己写了一个简单的脚本去抓取,见 Gist。
用 orgparse 解析 org-mode 文件
我的工作日志和日记都是 org-mode 文件,本质上里面的内容是一个树形的结构,最开始是自己写代码去解析的,后来换成了 orgparse 这个 Python 的 org-mode 解析器。
orgparse 可以直接将 org-mode 文件内容解析成一棵树,这样我在处理工作日志和个人日记时只要去遍历这棵树就好了
import orgparse content = ''' * 2024-01-17 周三 ** 12:05 能做的事情 blablablabla ** 16:01 怠惰 blablablabla ** 17:44 编制 blablablabla ** 22:06 今日回顾 blablablabla * 2024-01-18 周四 ''' tree = orgparse.loads(content) for node in tree.children: print(node) # 结果: # * 2024-01-17 周三 # * 2024-01-18 周四
然后任务下面的 clock 记录它也会解析出来
import orgparse content = ''' * 休闲 ** SOMETIME 看电影 :LOGBOOK: CLOCK: [2023-12-21 四 18:10]--[2023-12-21 四 21:20] => 3:10 - 狗神 CLOCK: [2023-10-04 三 14:59]--[2023-10-04 三 17:28] => 2:29 - 俄罗斯火车大劫案 :END: ''' tree = orgparse.loads(content) for level_1_node in tree.children: for level_2_node in level_1_node.children: for item in level_2_node.clock: print(item) # 结果 # [2023-12-21 Thu 18:10]--[2023-12-21 Thu 21:20] # [2023-10-04 Wed 14:59]--[2023-10-04 Wed 17:28]
不过有点可惜的是解析出来的 clock 记录把 note 丢掉了,所以我只用来做大类的时间统计,有些依赖里面内容的分析我还是自己做的。
用 LTP 进行分词/词性标注/实体识别等文本分析
要绘制词云就需要从文本里提取关键词,所以分词是必需的。再进一步的关键词提取,虽然也有很多工具,但这些工具基本上都是面向某个领域的,和我自己的日记、日志并不太匹配,所以我就采取了一些简单的策略来做关键词提取,反正也只是用来画一个词云,马马虎虎就行。
具体来说,这个策略是这样的:
- 先对文本进行分词、词性标注(标记每个词是名词、形容词、动词还是别的什么)、实体识别(人名、地名、机构名等)
- 反向过滤:若词中包含标点符号则去除,若词在停用词表中则去除,若词的词性为我设定的类别(连词、助词、叹词、量词、数词、介词、非语素词、时间名词)则去除(LTP 使用的词性标注集是 2005 年颁布的《信息处理用现代汉语词类标记规范》)、若词中字数太少(1个字的往往无意义)或太多(字数太多可能分词出错了)则去除
- 正向筛选:识别为实体的词一律选中作为关键词,我预先设置的一些重要词汇一律都选中作为关键词
能进行分词、词性标注、实体识别的工具很多,21 年的时候我用的是 jieba ,它的好处是依赖干净而且比较快,但效果要差一些而且没有实体识别功能。除了 jieba 还可以用北大的 pkuseg、哈工大的 LTP、百度的 LAC,当然国外的 spaCy 和斯坦福大学的 Stanza 也有中文支持都是不错的,我个人建议 pkuseg 或者 LTP。2023 年的年度分析我最后选了 LTP,是因为 LTP 在持续地更新,4.0 后已经升级成了 pytorch 模型想尝试下。
LTP 的模型建议像我一样自己下载好放到本地,否则它会去从已经被大陆屏蔽的 Huggingface 上下载而失败出错。
from ltp import LTP ltp = LTP('/home/zmonster/Projects/ltp/small/') output = ltp.pipeline(['思考晚上吃什么最后决定煮面吃,然后在整理日记的时候看到自己有一天空气炸锅了头一天 KFC 疯狂星期四买的鸡米花,想起来了之前自己还买过小酥肉放冰箱了,翻出来准备空气炸锅热了晚上吃一点。'], tasks=['cws', 'pos', 'ner']) print(output.cws) # [['思考', '晚上', '吃', '什么', '最后', '决定', '煮', '面', '吃', ',', '然后', '在', '整理', '日记', '的', '时候', '看到', '自己', '有', '一', '天', '空气', '炸锅', '了', '头', '一', '天 ', 'KFC ', '疯狂', '星期四', '买', '的', '鸡米花', ',', '想', '起来', '了', '之前', '自己', '还', '买', '过', '小', '酥肉', '放', '冰箱', '了', ',', '翻', '出来', '准备', '空气', '炸锅', '热', '了', '晚上', '吃', '一点', '。']] print(output.pos) # [['v', 'nt', 'v', 'r', 'nd', 'v', 'v', 'n', 'v', 'wp', 'c', 'p', 'v', 'n', 'u', 'n', 'v', 'r', 'v', 'm', 'q', 'n', 'v', 'u', 'm', 'm', 'q', 'nz', 'a', 'nt', 'v', 'u', 'n', 'wp', 'v', 'v', 'u', 'nd', 'r', 'd', 'v', 'u', 'a', 'n', 'v', 'n', 'u', 'wp', 'v', 'v', 'v', 'n', 'v', 'v', 'u', 'nt', 'v', 'm', 'wp']] print(output.ner) # [[]]
用 ImageMagick 进行简单的图像处理
我用 ImageMagick 来生成词云图需要的 mask 图使得画出来的词云能按照我预想的形状展示:
用 ImageMagick 绘制一张黑底白字写着 2023 的图
convert -background black -fill white -pointsize 512 label:2023 2023.png

用 ImageMagick 绘制一个直径 400 像素的圆
convert -size 400x400 xc:white -fill black -draw 'circle 200,200 200,3' circle400.png
然后我还很常用 ImageMagick 来裁剪一下图像的白边使得图像显得更紧凑一些,随后讲到的绘制热力图的 july 产生的结果就会有特别大的一块白边,我希望它能少一些但它又没有提供什么选项来让我控制(matplotlib 的 tight_layout 完全没作用)所以只能用 ImageMagick 再处理一下了
convert -trim 2023_diary_heatmap.png /tmp/a.png mv /tmp/a.png 2023_diary_heatmap.png
裁剪前是这个样子的
裁剪后是这个样子
用 july 绘制日志/日记热力图
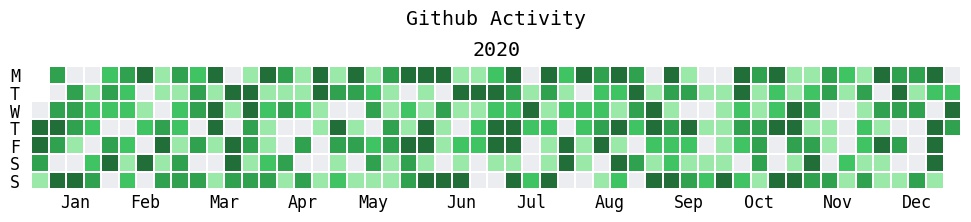
july 是一个基于 matplotlib 的用来绘制每日事件热力图的工具, 如下所示
import numpy as np import matplotlib.pyplot as plt import july from july.utils import date_range dates = date_range("2020-01-01", "2020-12-31") data = np.random.randint(0, 14, len(dates)) july.heatmap(dates, data, title='Github Activity', cmap="github")
会得到这样的图:
具体使用看项目 README 就好了,没有什么太特别的。不过如果想和我一样让显示的横坐标和纵坐标都是中文的话,需要在调用 july 前设置一下 locale
locale.setlocale(locale.LC_ALL, "zh_CN.UTF8")
另外就是在调用 july 的时候设置一下字体,这个在 README 的示例中有。
最近才看到 yihong 的 GithubPoster 感觉非常不错,之后也许就用 yihong 的这个工具了。
用 wordcloud 绘制词云
wordcloud 是基于 matplotlib 实现的词云绘制工具,它自己也提供了命令行工具直接从文本中读取数据然后绘制,但它里面自带的是按空白符进行分词的做法,也就是说不适用于中文文本。
好在它的 WordCloud 类实现了一个叫作 generate_from_frequencies 的方法,所以我是先在之前用 LTP 分词自己统计好频次后使用这个方法来绘制,像这样:
from wordcloud import WordCloud freqs = { '朋友': 432, '吃饭': 368, '游戏': 127, '聊天': 106, '晚饭': 83, '整理': 76, '午饭': 75, '早饭': 74, '洗漱': 60, '父母': 55 } wc = WordCloud(background_color='white', width=200, height=200) wc.generate_from_frequencies(freqs) wc.to_file('wordcloud.png')
不过它默认的实现不支持中文绘制,上面的代码会得到这样的图
通过 font_path 参数设置一下中文字体路径即可,我使用了文泉驿微米黑这个字体:
wc = WordCloud( background_color='white', width=200, height=200, font_path="/usr/share/fonts/truetype/wqy/wqy-microhei.ttc" )
这样就能得到

如果想要将词云绘制成特定的形状,就要使用前面用 ImageMagick 生成的 mask 图像了,通过 mask 参数传入对应的图像即可,最终会在 mask 图像的黑色区域绘制,比如使用前面那个圆形的 mask 图像:
from wordcloud import WordCloud from PIL import Image import numpy as np mask_image = np.array(Image.open('circle400.png')) freqs = { '朋友': 432, '吃饭': 368, '游戏': 127, '聊天': 106, '晚饭': 83, '整理': 76, '午饭': 75, '早饭': 74, '洗漱': 60, '父母': 55 } wc = WordCloud( background_color='white', mask=mask_image, width=len(mask_image[0]), height=len(mask_image), font_path="/usr/share/fonts/truetype/wqy/wqy-microhei.ttc", ) wc.generate_from_frequencies(freqs) wc.to_file('wordcloud.png')
结果如下图所示,虽然因为词比较少看着不太圆,但大体形状上能看出来和前面那张图的差别。

用 matplotlib_venn_wordcloud 绘制韦恩图形式的词云
韦恩图(Venn Diagram)是用来展示两个集合之间关系(是否有交集、交集部分有多少等)的一个图形,如下图所示:
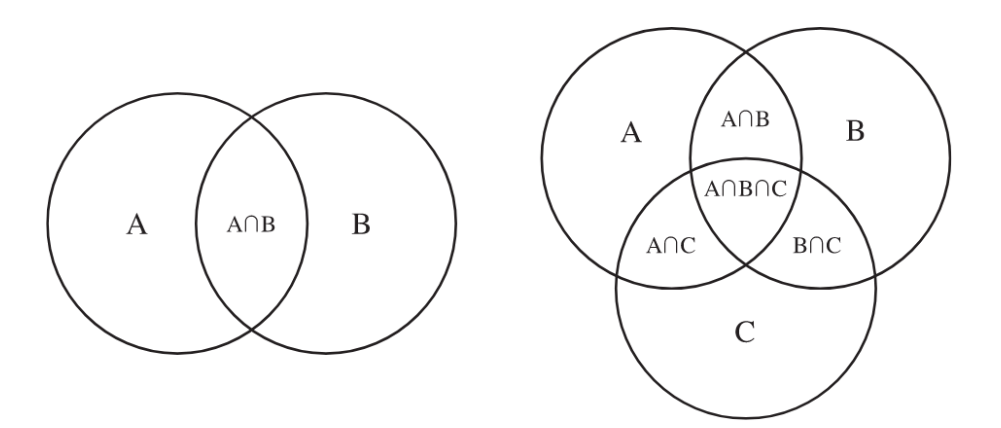
写《我的2021》分析聊天记录的时候,我想要分析我和一个特定的人交流的时候我们双方说的内容之间的同异同时又希望能把交流中高频的词突出显示,所以就想要在一个韦恩图形式的词云,具体来说是下面这个样子:

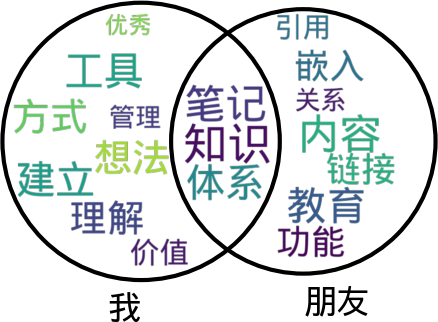
可以看到,总体上它还是一个词云图,但又引入了韦恩图的概念,左边的圆是我说过的话里的关键词、右边的图则是朋友说过的话里的关键词,两个圆的交集则是我们双方都说过的词。
这个是一个比较小众的需求,但最后还真找到了一个实现,也就是 matplotlib_venn_wordcloud 这个工具,其使用方法如下所示:
import matplotlib.pyplot as plt from matplotlib_venn_wordcloud import venn2_wordcloud plt.rcParams["font.sans-serif"] = ["WenQuanYi Micro Hei"] words = { '我': {'知识', '工具', '笔记', '建立', '体系', '管理', '方式', '想法', '价值', '优秀', '理解'}, '朋友': {'笔记', '知识', '体系', '内容', '教育', '嵌入', '引用', '功能', '链接', '关系'}, } freqs = { '知识': 69, '笔记': 68, '内容': 65, '体系': 63, '建立': 61, '工具': 61, '教育': 59, '方式': 57, '想法': 57, '理解': 55, '链接': 44, '嵌入': 44, '功能': 43, '价值': 32, '引用': 27, '管理': 25, '关系': 23, '优秀': 19, } names, sets = list(zip(*words.items())) venn2_wordcloud( [set(item) for item in sets], alpha=0.8, set_labels=names, word_to_frequency=freqs, wordcloud_kwargs={ 'font_path': '/usr/share/fonts/truetype/wqy/wqy-microhei.ttc', } ) plt.savefig('venn_wordcloud.png')
由于这个工具对中文支持也不是很好,所以需要像我上面的代码一样,分别在两处设置一下中文字体。
上面的代码会得到如下的图像:
用 matplotlib.pyplot.subplot_mosaic 进行布局设置
除此以外的大部分图像如柱状图、线图、饼图等我都是用 pandas 和 matplotlib 来绘制的,这一块的公开资料很多,所以这里只提一下要在一张图里画多个图表时设置布局的心得,具体来说是用 matplotlib.pyplot.subplot_mosaic 这个函数,它可以用比较直观地方式进行绘图的布局设计 —— 图像分为几行几列、某一个子图占据哪几行哪几列之类的,比如说:
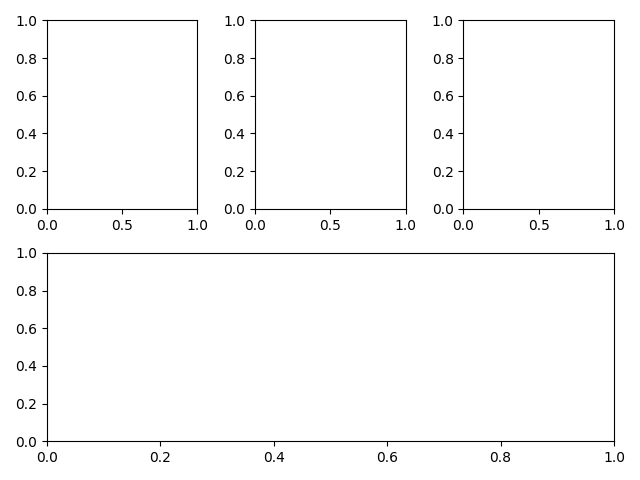
绘制 A/B/C/D 四个子图,A/B/C 一起在第一行并且各占 1/3 的宽度,子图 D 占据第二行整行
import matplotlib.pyplot as plt plt.subplot_mosaic('ABC;DDD')
上面的代码会得到下面的布局:
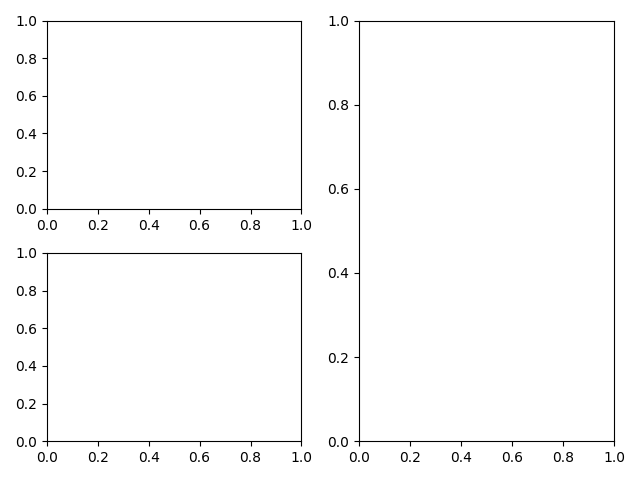
绘制 A/B/C 三个子图,A/B 一起在第一列并且各占 1/2 的高度,C 占据第二列整列
import matplotlib.pyplot as plt plt.subplot_mosaic('AC;BC')
上面的代码会得到下面的布局:
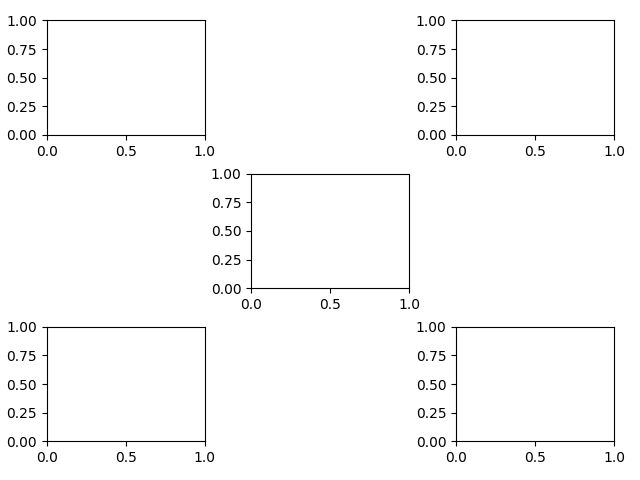
绘制一个 3x3 的布局,但只在中心和 4 个角进行绘图
import matplotlib.pyplot as plt plt.subplot_mosaic([ ['A', '.', 'B'], ['.', 'C', '.'], ['D', '.', 'E'], ])
上面的代码会得到下面的布局: